
Have you considered how the efficiency of your ML fashions may be enhanced with out creating new fashions? That’s the place switch studying comes into play. On this article, we are going to present an outline of switch studying together with its advantages and challenges.
What’s Switch Studying?
Switch studying implies that a mannequin skilled for one job can be utilized for an additional related job. You possibly can then use a pre-trained mannequin and make modifications in it based on the required job. Let’s talk about the phases in switch studying.
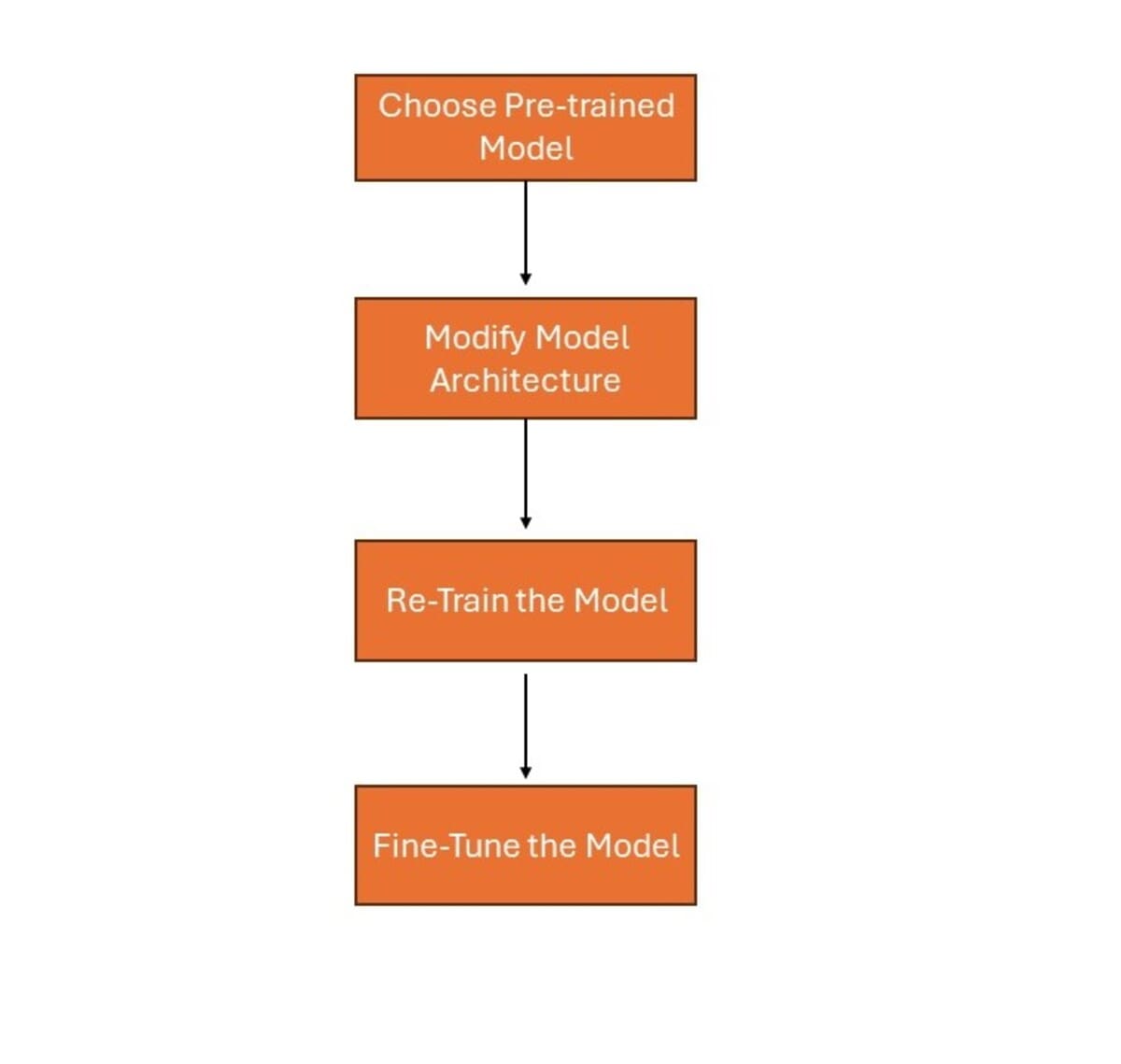
Picture by Creator
- Select a Pre-trained mannequin: Choose a mannequin that has been skilled on a big dataset for the same job to the one you need to work on.
- Modify mannequin structure: Regulate the ultimate layers of the pre-trained mannequin based on your particular job. Additionally, add new layers if wanted.
- Re-train the mannequin: Practice the modified mannequin in your new dataset. This permits the mannequin to be taught the main points of your particular job. It additionally advantages from the options it realized throughout the unique coaching.
- Superb-tune the mannequin: Unfreeze a number of the pre-trained layers and proceed coaching your mannequin. This permits the mannequin to higher adapt to the brand new job by fine-tuning its weights.
Advantages of Switch Studying
Switch studying gives a number of important benefits:
- Saves Time and Assets: Superb-tuning wants lesser time and computational sources because the pre-trained mannequin has been initially skilled for a lot of iterations for a selected dataset. This course of has already captured important options, so it reduces the workload for the brand new job.
- Improves Efficiency: Pre-trained fashions have realized from in depth datasets, so that they generalize higher. This results in improved efficiency on new duties, even when the brand new dataset is comparatively small. The data gained from the preliminary coaching helps in attaining greater accuracy and higher outcomes.
- Wants Much less Knowledge: One of many main advantages of switch studying is its effectiveness with smaller datasets. The pre-trained mannequin has already acquired helpful sample and options data. Thus, it will possibly carry out pretty even whether it is given few new knowledge.
Forms of Switch Studying
Switch studying may be categorized into three varieties:
Function extraction
Function extraction means utilizing options realized by a mannequin on new knowledge. As an illustration, in picture classification, we will make the most of options from a predefined Convolutional Neural Community to seek for important options in photographs. Right here’s an instance utilizing a pre-trained VGG16 mannequin from Keras for picture function extraction:
import numpy as np
from tensorflow.keras.functions import VGG16
from tensorflow.keras.preprocessing import picture
from tensorflow.keras.functions.vgg16 import preprocess_input
# Load pre-trained VGG16 mannequin (with out the highest layers for classification)
base_model = VGG16(weights='imagenet', include_top=False)
# Perform to extract options from a picture
def extract_features(img_path):
img = picture.load_img(img_path, target_size=(224, 224)) # Load picture and resize
x = picture.img_to_array(img) # Convert picture to numpy array
x = np.expand_dims(x, axis=0) # Add batch dimension
x = preprocess_input(x) # Preprocess enter based on mannequin's necessities
options = base_model.predict(x) # Extract options utilizing VGG16 mannequin
return options.flatten() # Flatten to a 1D array for simplicity
# Instance utilization
image_path = 'path_to_your_image.jpg'
image_features = extract_features(image_path)
print(f"Extracted options form: {image_features.form}")
Superb-tuning
Superb-tuning entails tweaking the function extraction steps and the features of a brand new mannequin matching the precise job. This technique is most helpful with a mid-sized knowledge set and the place you want to improve a selected task-related capability of the mannequin. For instance, in NLP, a normal BERT mannequin may be adjusted or additional skilled on a small amount of medical texts to perform medical entity recognition higher. Right here’s an instance utilizing BERT for sentiment evaluation with fine-tuning on a customized dataset:
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
import torch
from torch.utils.knowledge import DataLoader, TensorDataset
# Instance knowledge (change along with your dataset)
texts = ["I love this product!", "This is not what I expected.", ...]
labels = [1, 0, ...] # 1 for optimistic sentiment, 0 for detrimental sentiment, and so on.
# Load pre-trained BERT mannequin and tokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
mannequin = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # Instance: binary classification
# Tokenize enter texts and create DataLoader
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
dataset = TensorDataset(inputs['input_ids'], inputs['attention_mask'], torch.tensor(labels))
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# Superb-tuning parameters
optimizer = AdamW(mannequin.parameters(), lr=1e-5)
# Superb-tune BERT mannequin
mannequin.prepare()
for epoch in vary(3): # Instance: 3 epochs
for batch in dataloader:
optimizer.zero_grad()
input_ids, attention_mask, goal = batch
outputs = mannequin(input_ids, attention_mask=attention_mask, labels=goal)
loss = outputs.loss
loss.backward()
optimizer.step()
Area adaptation
Area adaptation offers an perception on how one can make the most of data gained from the supply area that the pre-trained mannequin was skilled on to the totally different goal area. That is required when the supply and goal domains differ on the options, the information distribution, and even on the language. As an illustration, in sentiment evaluation we might apply a sentiment classifier realized from product critiques into social media posts as a result of the 2 makes use of very totally different language. Right here’s an instance utilizing sentiment evaluation, adapting from product critiques to social media posts:
# Perform to adapt textual content type
def adapt_text_style(textual content):
# Instance: change social media language with product review-like language
adapted_text = textual content.change("excited", "optimistic").change("#innovation", "new expertise")
return adapted_text
# Instance utilization of area adaptation
social_media_post = "Excited concerning the new tech! #innovation"
adapted_text = adapt_text_style(social_media_post)
print(f"Tailored textual content: {adapted_text}")
# Use sentiment classifier skilled on product critiques
# Instance: sentiment_score = sentiment_classifier.predict(adapted_text)
Pre-trained Fashions
Pretrained fashions are fashions already skilled on giant datasets. They seize data and patterns from in depth knowledge. These fashions are used as a place to begin for different duties. Let’s talk about a number of the frequent pre-trained fashions utilized in machine studying: functions.
VGG (Visible Geometry Group)
The structure of VGG embrace a number of layers of three×3 convolutional filters and pooling layers. It is ready to determine detailed options like edges and shapes in photographs. By coaching on giant datasets, VGG learns to acknowledge totally different objects inside photographs. It will probably used for object detection and picture segmentation.
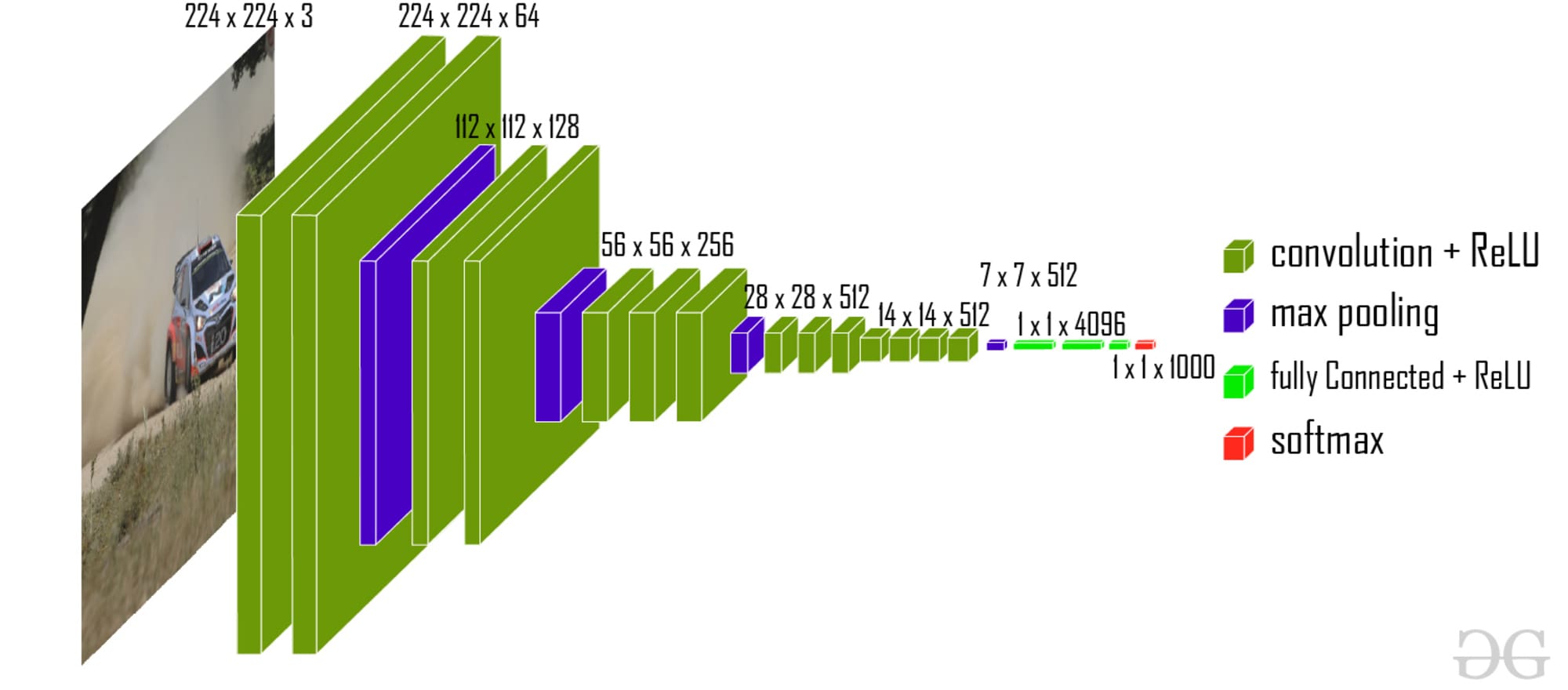
VGG-16 | CNN mannequin ( Supply: GeeksforGeeks)
ResNet (Residual Community)
ResNet makes use of residual connections to coach fashions. These connections make it simpler for gradients to circulate via the community. This prevents the vanishing gradient drawback, serving to the community prepare successfully. ResNet can efficiently prepare fashions with a whole bunch of layers. ResNet is great for duties akin to picture classification and face recognition.
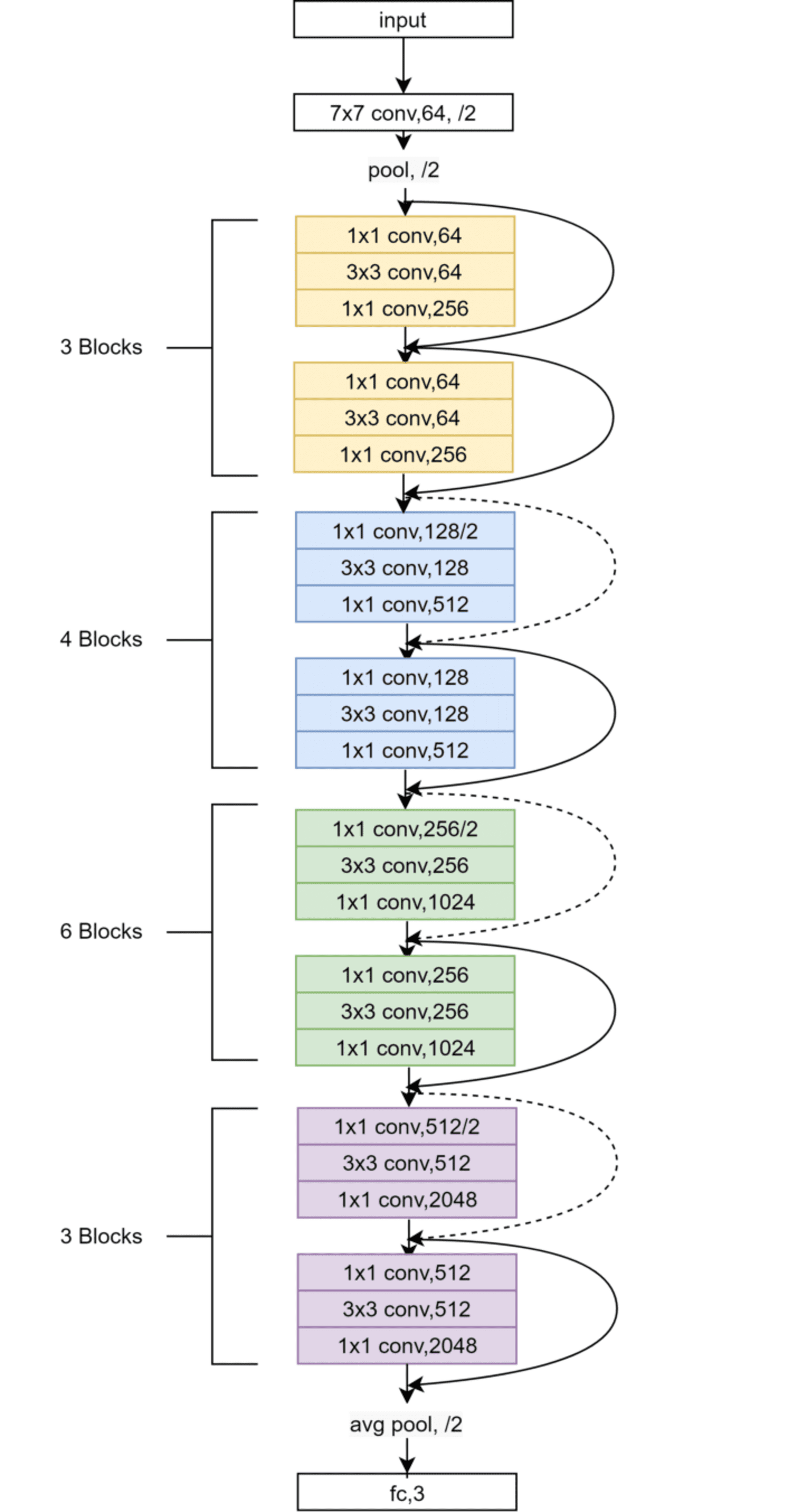
ResNet-50 Structure (Supply: Analysis Paper)
BERT (Bidirectional Encoder Representations from Transformers)
BERT is used for pure language processing functions. It makes use of a transformer-based mannequin to grasp the context of phrases in a sentence. It learns to guess lacking phrases and perceive sentence meanings. BERT can be utilized for sentiment evaluation, query answering and named entity recognition.
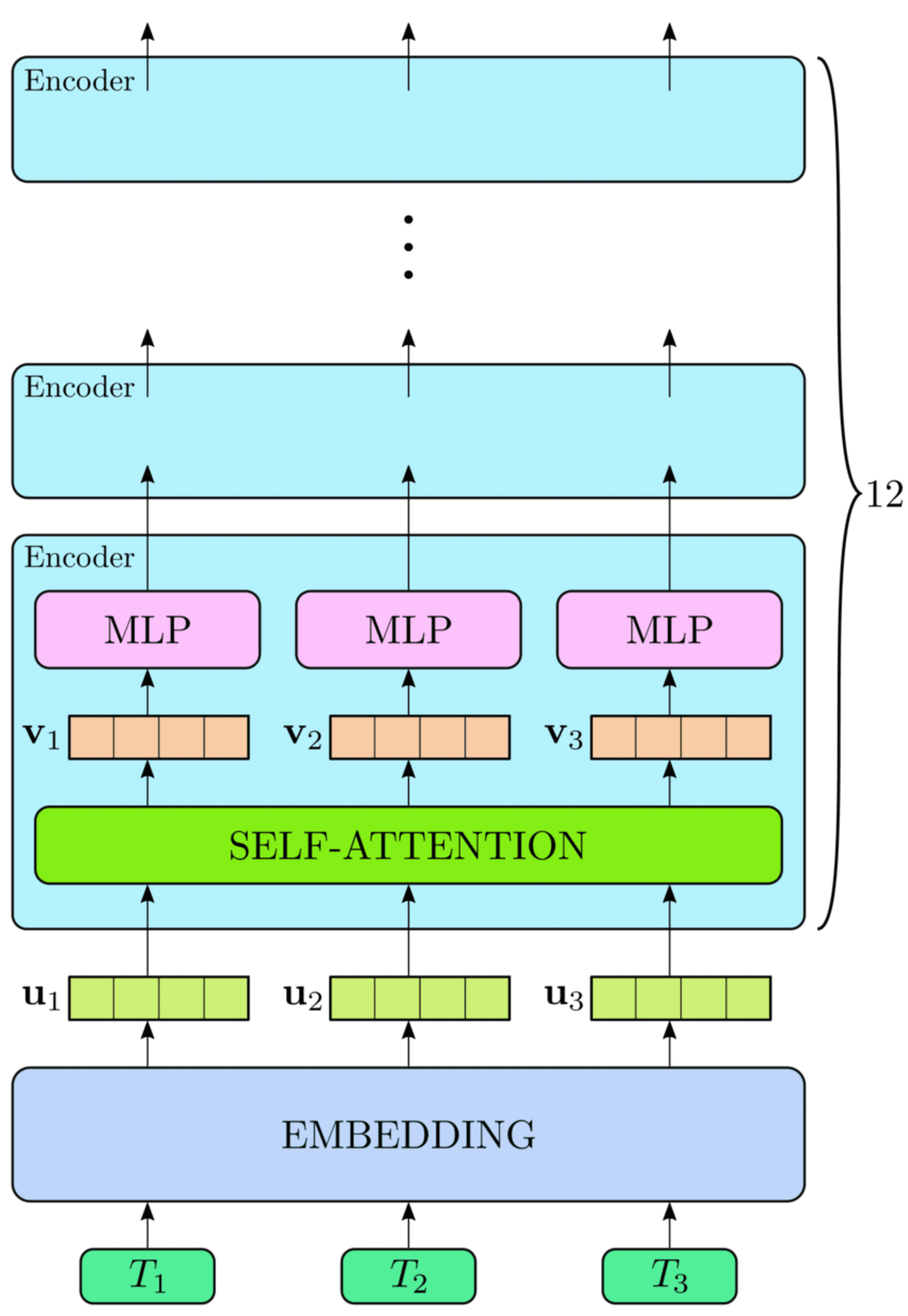
Excessive-level View of the BERT Structure (Supply: Analysis Paper)
Superb-tuning Strategies
Layer Freezing
Layer freezing means selecting sure layers of a pre-trained mannequin and stopping them from altering throughout coaching with new knowledge. That is completed to protect the helpful patterns and options the mannequin realized from its unique coaching. Sometimes, we freeze early layers that seize basic options like edges in photographs or primary constructions in textual content.
Studying Fee Adjustment
Tuning the educational fee is vital to steadiness what the mannequin has realized and new knowledge. Normally, fine-tuning entails utilizing a decrease studying fee than within the preliminary coaching with giant datasets. This helps the mannequin adapt to new knowledge whereas preserving most of its realized weights.
Challenges and Issues
Let’s talk about the challenges of switch studying and tips on how to deal with them.
- Dataset Dimension and Area Shift: When fine-tuning, there must be plentiful of information for the duty involved whereas fine-tuning generalized fashions. The disadvantage of this method is that in case the brand new dataset is both small or considerably totally different from what matches the mannequin at the start. To take care of this, one can put extra knowledge which will probably be extra related to what the mannequin already skilled on.
- Hyperparameter Tuning: Altering hyperparameters is vital when working with pre skilled fashions. These parameters are depending on one another and decide how good the mannequin goes to be. Strategies akin to grid search or automated instruments to seek for essentially the most optimum settings for hyperparameters that will yield excessive efficiency on validation knowledge.
- Computational Assets: Superb-tuning of deep neural networks is computationally demanding as a result of such fashions can have thousands and thousands of parameters. For coaching and predicting the output, highly effective accelerators like GPU or TPU are required. These calls for are often addressed by the cloud computing platforms.
Wrapping Up
In conclusion, switch studying stands as a cornerstone within the quest to boost mannequin efficiency throughout numerous functions of synthetic intelligence. By leveraging pretrained fashions like VGG, ResNet, BERT, and others, practitioners can effectively harness present data to sort out advanced duties in picture classification, pure language processing, healthcare, autonomous programs, and past.
Jayita Gulati is a machine studying fanatic and technical author pushed by her ardour for constructing machine studying fashions. She holds a Grasp’s diploma in Laptop Science from the College of Liverpool.