Picture by Writer
Machine Studying Interpretability
Machine studying interpretability refers to methods for explaining and understanding how machine studying fashions make predictions. As fashions change into extra complicated, it turns into more and more necessary to clarify their inner logic and achieve insights into their habits.
That is necessary as a result of machine studying fashions are sometimes used to make selections which have real-world penalties, corresponding to in healthcare, finance, and felony justice. With out interpretability, it may be troublesome to know whether or not a machine studying mannequin is making good selections or whether it is biased.
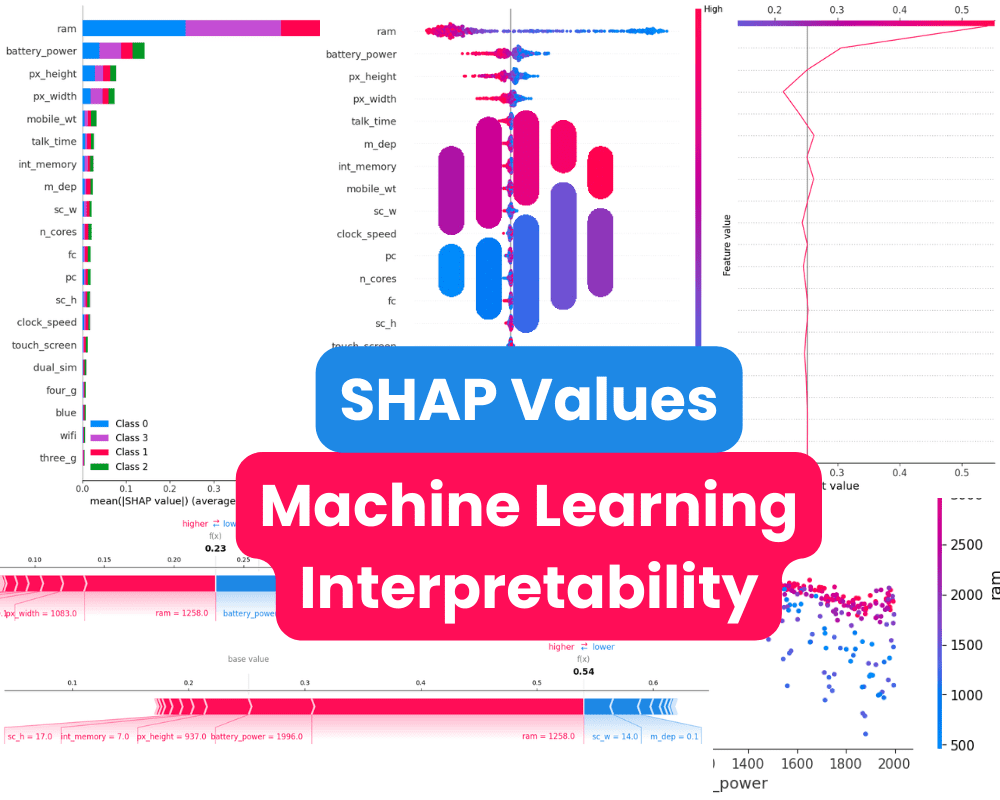
In the case of machine studying interpretability, there are numerous methods to think about. One common methodology is to find out function significance scores, which reveal the options which have the best influence on the mannequin’s predictions. SKlearn fashions supply function significance scores by default, however you may also make the most of instruments like SHAP, Lime, and Yellowbrick for higher visualization and understanding of your machine studying outcomes.
This tutorial will cowl SHAP values and find out how to interpret machine studying outcomes with the SHAP Python bundle.
What are SHAP Values?
SHAP values are primarily based on Shapley values from sport concept. In sport concept, Shapley values assist decide how a lot every participant in a collaborative sport has contributed to the full payout.
For a machine studying mannequin, every function is taken into account a “participant”. The Shapley worth for a function represents the typical magnitude of that function’s contribution throughout all doable mixtures of options.
Particularly, SHAP values are calculated by evaluating a mannequin’s predictions with and with no specific function current. That is executed iteratively for every function and every pattern within the dataset.
By assigning every function an significance worth for each prediction, SHAP values present a neighborhood, constant rationalization of how the mannequin behaves. They reveal which options have probably the most influence on a selected prediction, whether or not positively or negatively. That is helpful for understanding the reasoning behind complicated machine studying fashions corresponding to deep neural networks.
Getting Began with SHAP Values
On this part, we’ll use the Cell Worth Classification dataset from Kaggle to construct and analyze multi classification fashions. We shall be classifying cell phone costs primarily based on the options, corresponding to ram, dimension, and so forth. The goal variable is <code>price_range</code> with values of 0(low price), 1(medium price), 2(excessive price) and three(very excessive price).
Observe: Code supply with outputs is out there at Deepnote workspace.
Putting in SHAP
It’s fairly easy to put in <code>shap</code> in your system utilizing <code>pip</code> or <code>conda</code> instructions.
pip set up shap
or
conda set up -c conda-forge shap
Loading the information
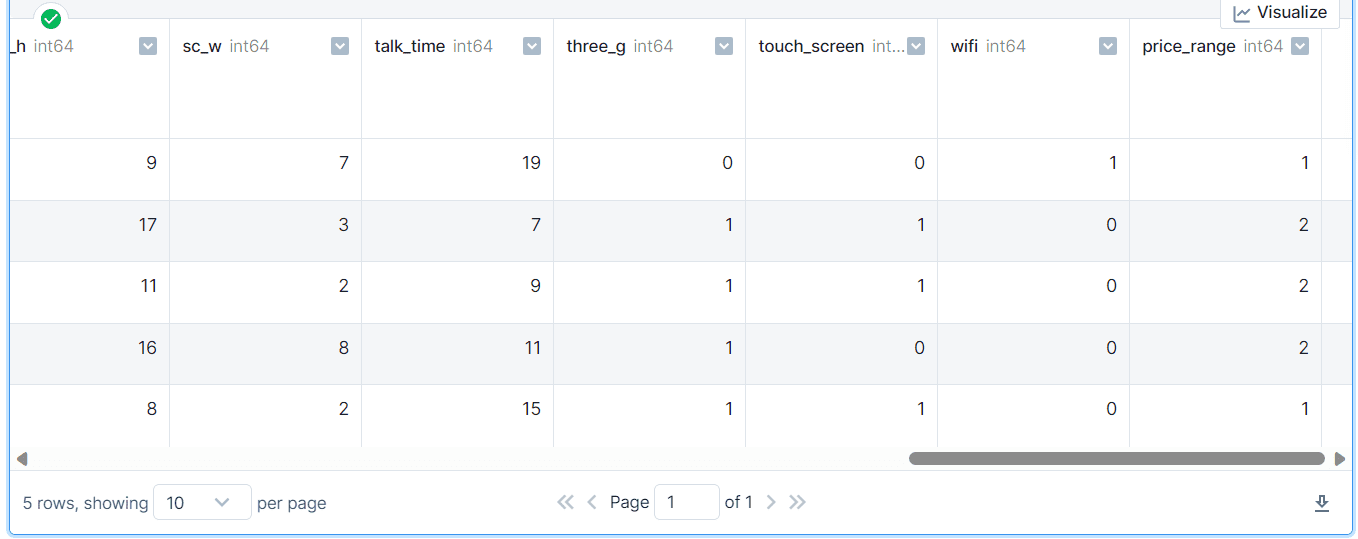
The dataset is clear and well-organized, with classes transformed to numerical utilizing label encoders.
import pandas as pd
cell = pd.read_csv("practice.csv")
cell.head()
Making ready the information
To start, we’ll establish the dependent and impartial variables after which break up them into separate coaching and testing units.
from sklearn.model_selection import train_test_split
X = cell.drop('price_range', axis=1)
y = cell.pop('price_range')
# Prepare and check break up
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
Coaching and evaluating the mannequin
After that, we’ll practice our Random Forest classifier mannequin utilizing the coaching set and consider its efficiency on the testing set. We now have obtained an accuracy of 87%, which is sort of good, and our mannequin is well-balanced general.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Mannequin becoming
rf = RandomForestClassifier()
rf.match(X_train, y_train)
# Prediction
y_pred = rf.predict(X_test)
# Mannequin analysis
print(classification_report(y_pred, y_test))
precision recall f1-score help
0 0.95 0.91 0.93 141
1 0.83 0.81 0.82 153
2 0.80 0.85 0.83 158
3 0.93 0.93 0.93 148
accuracy 0.87 600
macro avg 0.88 0.87 0.88 600
weighted avg 0.87 0.87 0.87 600
Calculating SHAP Worth
On this half, we’ll create an SHAP tree explainer and use it to calculate SHAP values of the testing set.
import shap
shap.initjs()
# Calculate SHAP values
explainer = shap.TreeExplainer(rf)
shap_values = explainer.shap_values(X_test)
Abstract Plot
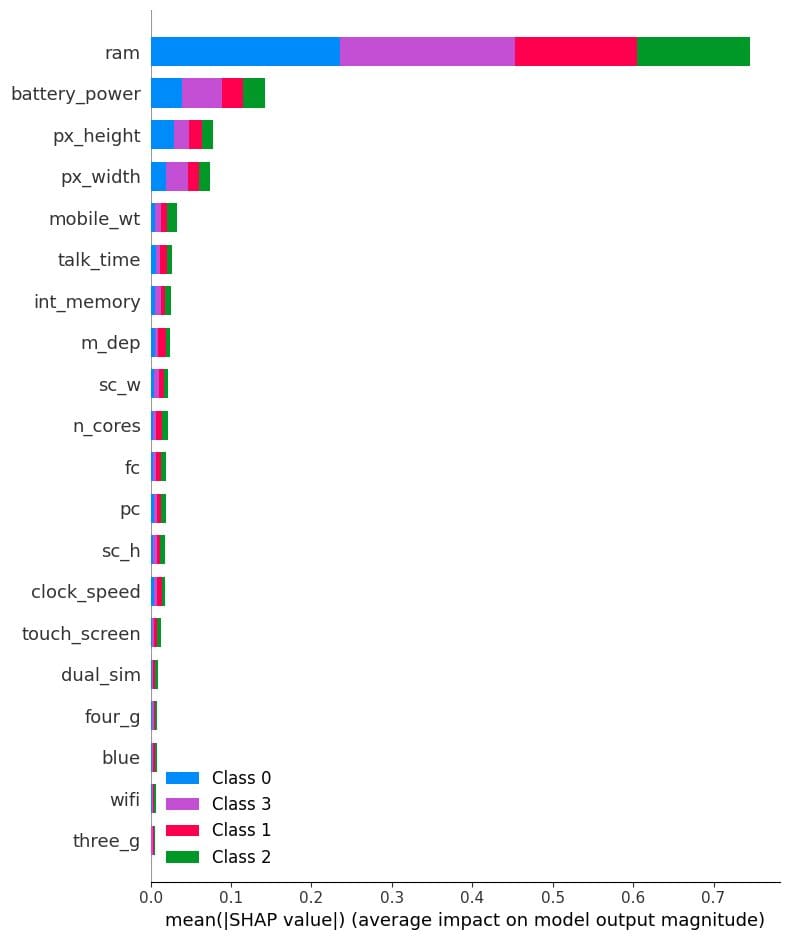
The abstract plot is a graphical illustration of the function significance of every function within the mannequin. It’s a useful gizmo for understanding how the mannequin makes predictions and for figuring out a very powerful options.
In our case, it exhibits function significance per goal class. It seems the “ram”, “battery_power”, and dimension of the cellphone play an necessary position in figuring out the value vary.
# Summarize the results of options
shap.summary_plot(shap_values, X_test)
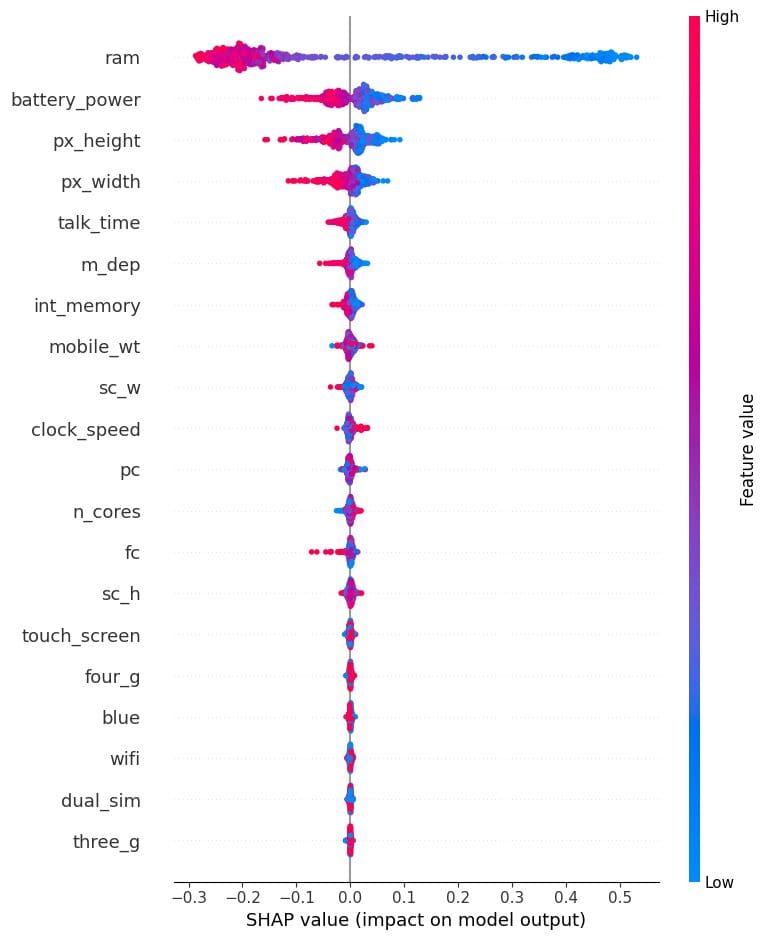
We’ll now visualize the longer term significance of the category “0”. We are able to clearly see that, ram, battery, and dimension of the cellphone have unfavourable results for predicting low price cell phones.
shap.summary_plot(shap_values[0], X_test)
Dependence Plot
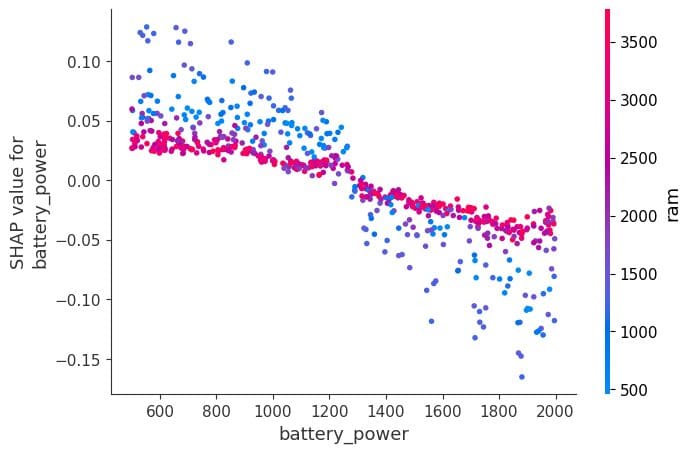
A dependence plot is a sort of scatter plot that shows how a mannequin’s predictions are affected by a selected function. On this instance, the function is “battery_power”.
The x-axis of the plot exhibits the values of “battery_power”, and the y-axis exhibits the shap worth. When the battery energy exceeds 1200, it begins to negatively have an effect on the classification of lower-end cell phone fashions.
shap.dependence_plot("battery_power", shap_values[0], X_test,interaction_index="ram")
Drive Plot
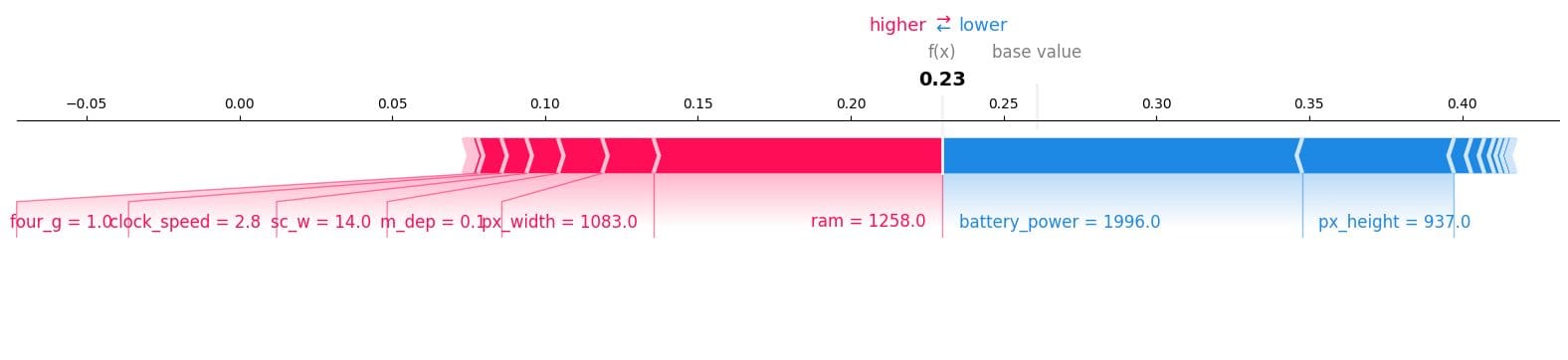
Let’s slim our focus to a single pattern. Particularly, we’ll take a more in-depth take a look at the twelfth pattern to see which options contributed to the “0” consequence. To perform this, we’ll use a drive plot and enter the anticipated worth, SHAP worth, and testing pattern.
It seems ram, cellphone dimension, and clock velocity have a better affect on fashions. We now have additionally observed that the mannequin won’t predict “0” class because the f(x) is decrease.
shap.plots.drive(explainer.expected_value[0], shap_values[0][12,:], X_test.iloc[12, :], matplotlib = True)
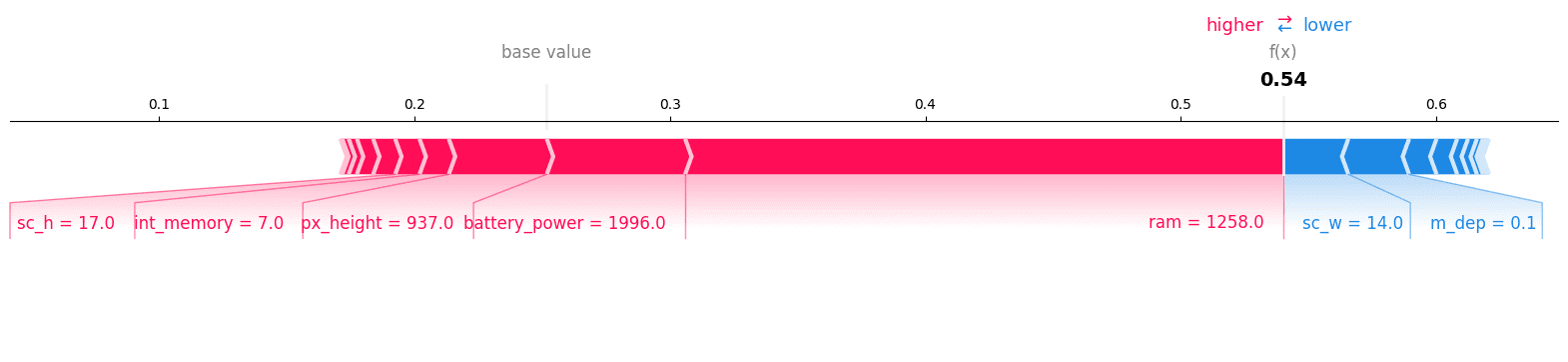
We’ll now visualize the drive plot for the category ”1”, and we will see that it’s the proper class.
shap.plots.drive(explainer.expected_value[1], shap_values[1][12, :], X_test.iloc[12, :],matplotlib = True)
We are able to verify our prediction by checking the twelfth file of the testing set.
y_test.iloc[12]
>>> 1
Resolution Plot
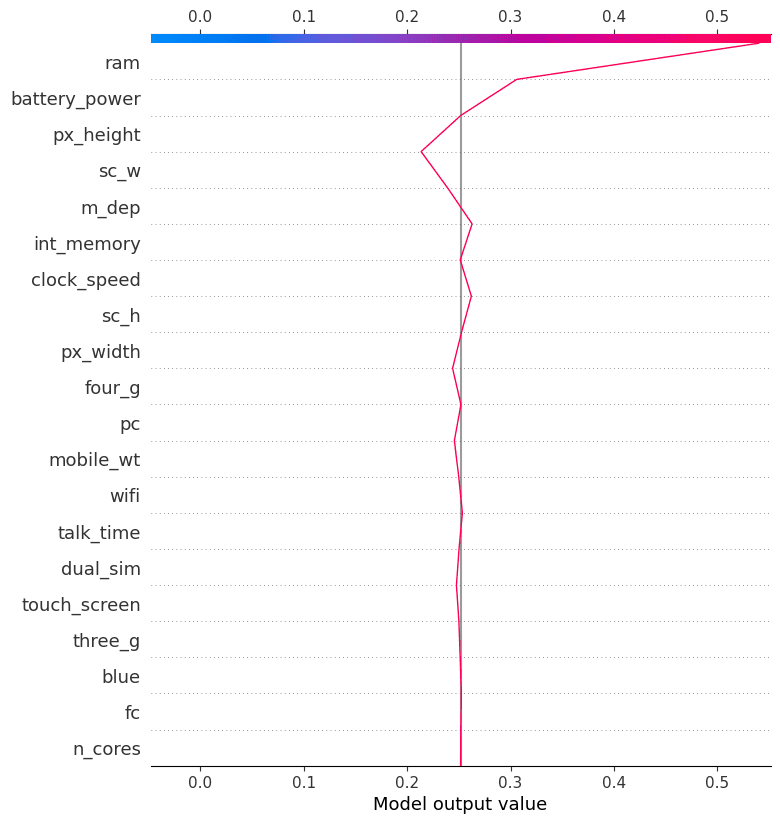
Resolution plots generally is a useful gizmo for understanding the decision-making means of a machine studying mannequin. They may help us to establish the options which can be most necessary to the mannequin’s predictions and to establish potential biases.
To higher perceive the elements that influenced the mannequin’s prediction of sophistication “1”, we’ll look at the choice plot. Primarily based on this plot, it seems that cellphone top had a unfavourable influence on the mannequin, whereas RAM had a optimistic influence.
shap.decision_plot(explainer.expected_value[1], shap_values[1][12,:], X_test.columns)
Conclusion
On this weblog publish, we’ve launched SHAP values, a technique for explaining the output of machine studying fashions. We now have proven how SHAP values can be utilized to clarify particular person predictions and the general efficiency of a mannequin. We now have additionally supplied examples of how SHAP values can be utilized in follow.
As machine studying expands into delicate domains like healthcare, finance, and autonomous automobiles, interpretability and explainability will solely develop in significance. SHAP values supply a versatile, constant method to explaining predictions and mannequin habits. It may be used to achieve insights into how the fashions make predictions, establish potential biases, and enhance the fashions’ efficiency.
Abid Ali Awan (@1abidaliawan) is a licensed knowledge scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in Expertise Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids combating psychological sickness.