
Picture by Writer
Massive Language Fashions (LLMs) like GPT-4 and LLaMA2 have entered the [data labeling] chat. LLMs have come a good distance and might now label knowledge and tackle duties traditionally performed by people. Whereas acquiring knowledge labels with an LLM is extremely fast and comparatively low cost, there’s nonetheless one massive subject, these fashions are the last word black containers. So the burning query is: how a lot belief ought to we put within the labels these LLMs generate? In at the moment’s put up, we break down this conundrum to determine some basic pointers for gauging the boldness we are able to have in LLM-labeled knowledge.
Background
The outcomes offered under are from an experiment performed by Toloka utilizing common fashions and a dataset in Turkish. This isn’t a scientific report however slightly a brief overview of potential approaches to the issue and a few solutions for decide which methodology works finest in your utility.
The Large Query
Earlier than we get into the small print, right here’s the large query: When can we belief a label generated by an LLM, and when ought to we be skeptical? Realizing this may help us in automated knowledge labeling and may also be helpful in different utilized duties like buyer assist, content material technology, and extra.
The Present State of Affairs
So, how are individuals tackling this subject now? Some immediately ask the mannequin to spit out a confidence rating, some have a look at the consistency of the mannequin’s solutions over a number of runs, whereas others look at the mannequin’s log possibilities. However are any of those approaches dependable? Let’s discover out.
The Rule of Thumb
What makes a “good” confidence measure? One easy rule to comply with is that there ought to be a optimistic correlation between the boldness rating and the accuracy of the label. In different phrases, a better confidence rating ought to imply a better probability of being appropriate. You’ll be able to visualize this relationship utilizing a calibration plot, the place the X and Y axes symbolize confidence and accuracy, respectively.
Experiments and Their Outcomes
Strategy 1: Self-Confidence
The self-confidence method entails asking the mannequin about its confidence immediately. And guess what? The outcomes weren’t half unhealthy! Whereas the LLMs we examined struggled with the non-English dataset, the correlation between self-reported confidence and precise accuracy was fairly stable, that means fashions are properly conscious of their limitations. We obtained related outcomes for GPT-3.5 and GPT-4 right here.
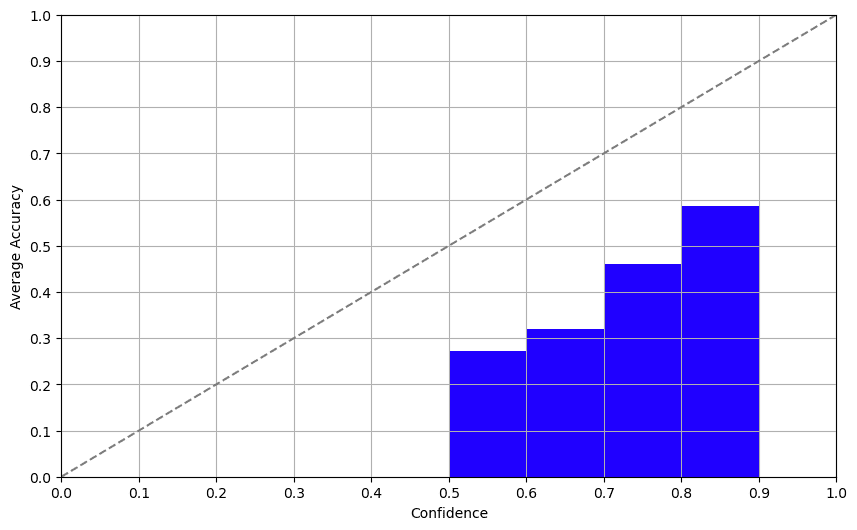
Strategy 2: Consistency
Set a excessive temperature (~0.7–1.0), label the identical merchandise a number of instances, and analyze the consistency of the solutions, for extra particulars, see this paper. We tried this with GPT-3.5 and it was, to place it flippantly, a dumpster hearth. We prompted the mannequin to reply the identical query a number of instances and the outcomes had been constantly erratic. This method is as dependable as asking a Magic 8-Ball for all times recommendation and shouldn’t be trusted.
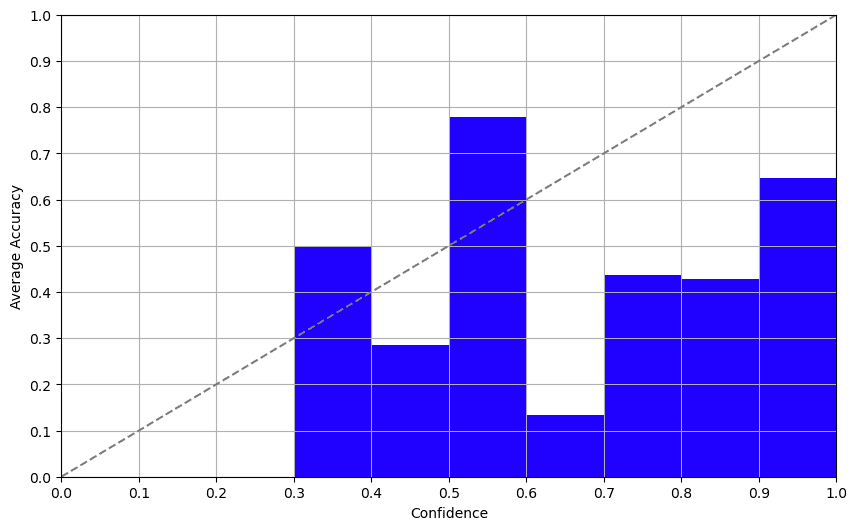
Strategy 3: Log Possibilities
Log possibilities provided a pleasing shock. Davinci-003 returns logprobs of the tokens within the completion mode. Analyzing this output, we obtained a surprisingly respectable confidence rating that correlated properly with accuracy. This methodology affords a promising method to figuring out a dependable confidence rating.
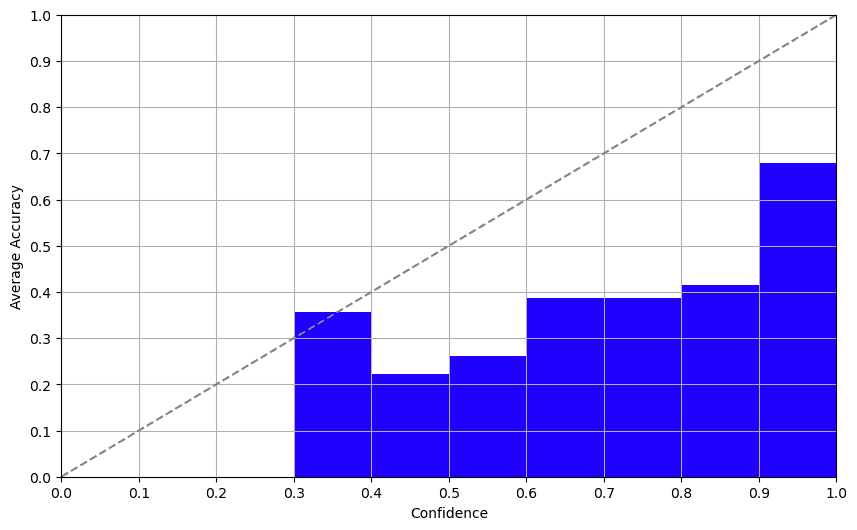
The Takeaway
So, what did we be taught? Right here it’s, no sugar-coating:
- Self-Confidence: Helpful, however deal with with care. Biases are reported extensively.
- Consistency: Simply don’t. Except you take pleasure in chaos.
- Log Possibilities: A surprisingly good wager for now if the mannequin permits you to entry them.
The thrilling half? Log possibilities look like fairly strong even with out fine-tuning the mannequin, regardless of this paper reporting this methodology to be overconfident. There’s room for additional exploration.
Future Avenues
A logical subsequent step could possibly be to discover a golden method that mixes one of the best elements of every of those three approaches, or explores new ones. So, when you’re up for a problem, this could possibly be your subsequent weekend challenge!
Wrapping Up
Alright, ML aficionados and newbies, that’s a wrap. Keep in mind, whether or not you’re engaged on knowledge labeling or constructing the subsequent massive conversational agent – understanding mannequin confidence is essential. Don’t take these confidence scores at face worth and be sure to do your homework!
Hope you discovered this insightful. Till subsequent time, maintain crunching these numbers and questioning these fashions.
Ivan Yamshchikov is a professor of Semantic Knowledge Processing and Cognitive Computing on the Middle for AI and Robotics, Technical College of Utilized Sciences Würzburg-Schweinfurt. He additionally leads the Knowledge Advocates staff at Toloka AI. His analysis pursuits embrace computational creativity, semantic knowledge processing and generative fashions.