XGBoost (eXtreme Gradient Boosting) is an open-source algorithm that implements gradient-boosting bushes with further enchancment for higher efficiency and pace. The algorithm’s fast skill to make correct predictions makes the mannequin a go-to mannequin for a lot of competitions, such because the Kaggle competitors.
The widespread circumstances for the XGBoost purposes are for classification prediction, reminiscent of fraud detection, or regression prediction, reminiscent of home pricing prediction. Nonetheless, extending the XGBoost algorithm to forecast time-series information can also be doable. How is it really works? Let’s discover this additional.
Time-Collection Forecasting
Forecasting in information science and machine studying is a way used to foretell future numerical values based mostly on historic information collected over time, both in common or irregular intervals.
In contrast to widespread machine studying coaching information the place every remark is impartial of the opposite, information for time-series forecasts have to be in successive order and associated to every information level. For instance, time-series information might embody month-to-month inventory, weekly climate, every day gross sales, and so forth.
Let’s have a look at the instance time-series information Every day Local weather information from Kaggle.
import pandas as pd
prepare = pd.read_csv('DailyDelhiClimateTrain.csv')
take a look at = pd.read_csv('DailyDelhiClimateTest.csv')
prepare.head()
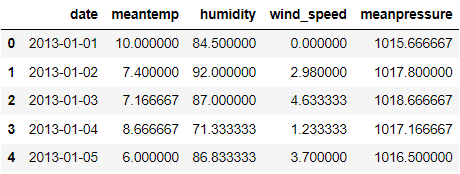
If we have a look at the dataframe above, each characteristic is recorded every day. The date column signifies when the information is noticed, and every remark is said.
Time-Collection forecast usually incorporate pattern, seasonal, and different patterns from the information to create forecasting. One straightforward method to take a look at the sample is by visualizing them. For instance, I might visualize the imply temperature information from our instance dataset.
prepare["date"] = pd.to_datetime(prepare["date"])
take a look at["date"] = pd.to_datetime(take a look at["date"])
prepare = prepare.set_index("date")
take a look at = take a look at.set_index("date")
prepare["meantemp"].plot(model="ok", figsize=(10, 5), label="prepare")
take a look at["meantemp"].plot(model="b", figsize=(10, 5), label="take a look at")
plt.title("Imply Temperature Dehli Knowledge")
plt.legend()
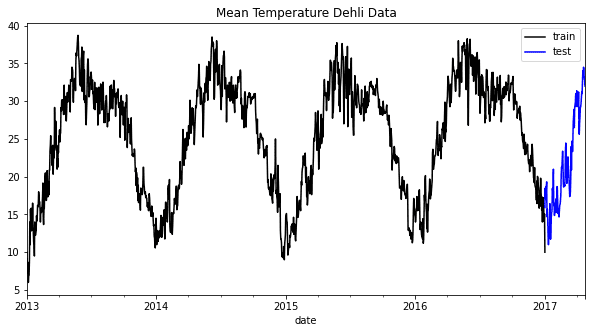
It’s straightforward for us to see within the graph above that every yr has a standard seasonality sample. By incorporating this info, we will perceive how our information work and determine which mannequin would possibly swimsuit our forecast mannequin.
Typical forecast fashions embody ARIMA, Vector AutoRegression, Exponential Smoothing, and Prophet. Nonetheless, we will additionally make the most of XGBoost to offer the forecasting.
XGBoost Forecasting
Earlier than making ready to forecast utilizing XGBoost, we should set up the package deal first.
pip set up xgboost
After the set up, we might put together the information for our mannequin coaching. In principle, XGBoost Forecasting would implement the Regression mannequin based mostly on the singular or a number of options to foretell future numerical values. That’s the reason the information coaching should even be within the numerical values. Additionally, to include the movement of time inside our XGBoost mannequin, we might rework the time information into a number of numerical options.
Let’s begin by making a operate to create the numerical options from the date.
def create_time_feature(df):
df['dayofmonth'] = df['date'].dt.day
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.yr
df['dayofyear'] = df['date'].dt.dayofyear
df['weekofyear'] = df['date'].dt.weekofyear
return df
Subsequent, we might apply this operate to the coaching and take a look at information.
prepare = create_time_feature(prepare)
take a look at = create_time_feature(take a look at)
prepare.head()
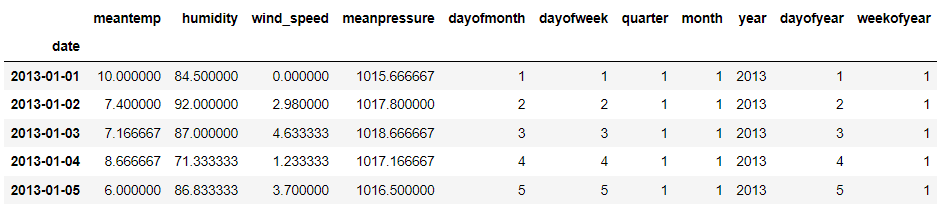
The required info is now all accessible. Subsequent, we might outline what we need to predict. On this instance, we might forecast the imply temperature and make the coaching information based mostly on the information above.
X_train = prepare.drop('meantemp', axis =1)
y_train = prepare['meantemp']
X_test = take a look at.drop('meantemp', axis =1)
y_test = take a look at['meantemp']
I might nonetheless use the opposite info, reminiscent of humidity, to point out that XGBoost may forecast values utilizing multivariate approaches. Nonetheless, in apply, we solely incorporate information that we all know exists after we attempt to forecast.
Let’s begin the coaching course of by becoming the information into the mannequin. For the present instance, we might not do a lot hyperparameter optimization apart from the variety of bushes.
import xgboost as xgb
reg = xgb.XGBRegressor(n_estimators=1000)
reg.match(X_train, y_train, verbose = False)
After the coaching course of, let’s see the characteristic significance of the mannequin.
xgb.plot_importance(reg)
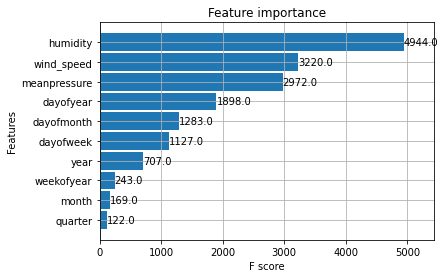
The three preliminary options should not surprisingly useful for forecasting, however the time options additionally contribute to the prediction. Let’s attempt to have the prediction on the take a look at information and visualize them.
take a look at['meantemp_Prediction'] = reg.predict(X_test)
prepare['meantemp'].plot(model='ok', figsize=(10,5), label = 'prepare')
take a look at['meantemp'].plot(model='b', figsize=(10,5), label = 'take a look at')
take a look at['meantemp_Prediction'].plot(model='r', figsize=(10,5), label = 'prediction')
plt.title('Imply Temperature Dehli Knowledge')
plt.legend()
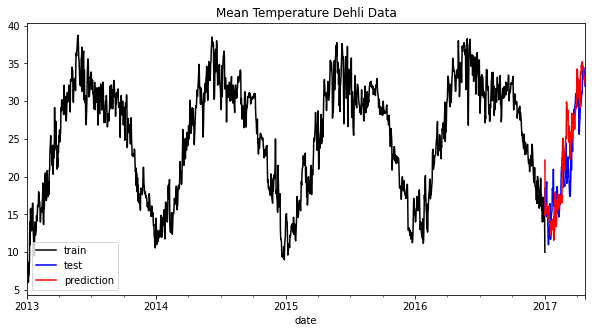
As we will see from the graph above, the prediction might sound barely off however nonetheless observe the general pattern. Let’s attempt to consider the mannequin based mostly on the error metrics.
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
print('RMSE: ', spherical(mean_squared_error(y_true=take a look at['meantemp'],y_pred=take a look at['meantemp_Prediction']),3))
print('MAE: ', spherical(mean_absolute_error(y_true=take a look at['meantemp'],y_pred=take a look at['meantemp_Prediction']),3))
print('MAPE: ', spherical(mean_absolute_percentage_error(y_true=take a look at['meantemp'],y_pred=take a look at['meantemp_Prediction']),3))
RMSE: 11.514
MAE: 2.655
MAPE: 0.133
The outcome exhibits that our prediction might have an error of round 13%, and the RMSE additionally exhibits a slight error within the forecast. The mannequin might be improved utilizing hyperparameter optimization, however we’ve got discovered how XGBoost can be utilized for the forecast.
Conclusion
XGBoost is an open-source algorithm usually used for a lot of information science circumstances and within the Kaggle competitors. Typically the use circumstances are widespread classification circumstances reminiscent of fraud detection or regression circumstances reminiscent of home value prediction, however XGBoost will also be prolonged into time-series forecasting. Through the use of the XGBoost Regressor, we will create a mannequin that may predict future numerical values.
Cornellius Yudha Wijaya is a knowledge science assistant supervisor and information author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Knowledge suggestions through social media and writing media.