
Picture by Unsplash
Within the machine studying course of, knowledge scaling falls beneath knowledge preprocessing, or characteristic engineering. Scaling your knowledge earlier than utilizing it for mannequin constructing can accomplish the next:
- Scaling ensures that options have values in the identical vary
- Scaling ensures that the options utilized in mannequin constructing are dimensionless
- Scaling can be utilized for detecting outliers
There are a number of strategies for scaling knowledge. The 2 most necessary scaling methods are Normalization and Standardization.
Knowledge Scaling Utilizing Normalization
When knowledge is scaled utilizing normalization, the remodeled knowledge may be calculated utilizing this equation
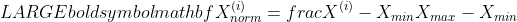
the place 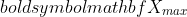 and
and 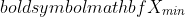 are the utmost and minimal values of the information, respectfully. The scaled knowledge obtained is within the vary [0, 1].
are the utmost and minimal values of the information, respectfully. The scaled knowledge obtained is within the vary [0, 1].
Python Implementation of Normalization
Scaling utilizing normalization may be carried out in Python utilizing the code under:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(knowledge)
Let X be a given knowledge with 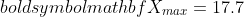 and
and 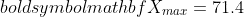 . The information X is proven within the determine under:
. The information X is proven within the determine under:
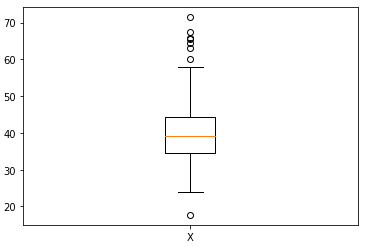
Determine 1. Boxplot of knowledge X with values between 17.7 and 71.4. Picture by Creator.
The normalized X is proven within the determine under:
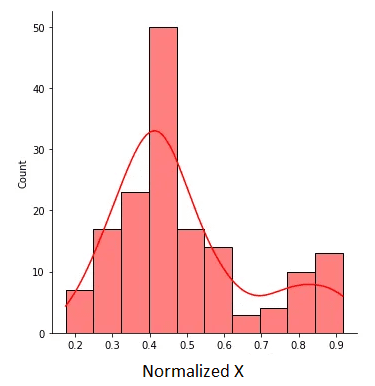
Determine 2. Normalized X with values between 0 and 1. Picture by Creator.
Knowledge Scaling Utilizing Standardization
Ideally, standardization must be used when the information is distributed in accordance with the conventional or Guassian distribution. The standardized knowledge may be calculated as follows:
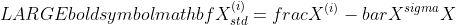
Right here, 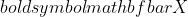 is the imply of the information, and
is the imply of the information, and 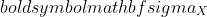 is the usual deviation. Standardized values ought to sometimes lie within the vary [-2, 2], which represents the 95% confidence interval. Standardized values lower than -2 or larger than 2 may be thought of as outliers. Due to this fact, standardization can be utilized for outlier detection.
is the usual deviation. Standardized values ought to sometimes lie within the vary [-2, 2], which represents the 95% confidence interval. Standardized values lower than -2 or larger than 2 may be thought of as outliers. Due to this fact, standardization can be utilized for outlier detection.
Python Implementation of Standardization
Scaling utilizing standardization may be carried out in Python utilizing the code under:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(knowledge)
Utilizing the information described above, the standardized knowledge is proven under:
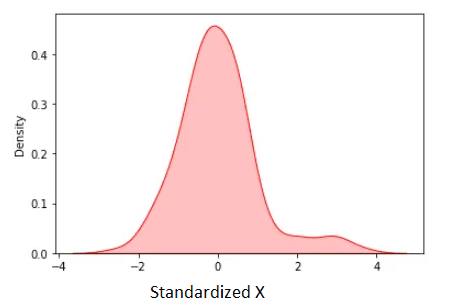
Determine 3. Standardized X. Picture by Creator.
The standardized imply is zero. We observe from the determine above that apart from some few outliers, many of the standardized knowledge lies within the vary [-2, 2].
Conclusion
In abstract, we’ve mentioned two of the preferred strategies for characteristic scaling, particularly: standardization and normalization. Normalized knowledge lies within the vary [0, 1], whereas standardized knowledge lies sometimes within the vary [-2, 2]. The benefit of standardization is that it may be used for outlier detection.
Benjamin O. Tayo is a Physicist, Knowledge Science Educator, and Author, in addition to the Proprietor of DataScienceHub. Beforehand, Benjamin was instructing Engineering and Physics at U. of Central Oklahoma, Grand Canyon U., and Pittsburgh State U.