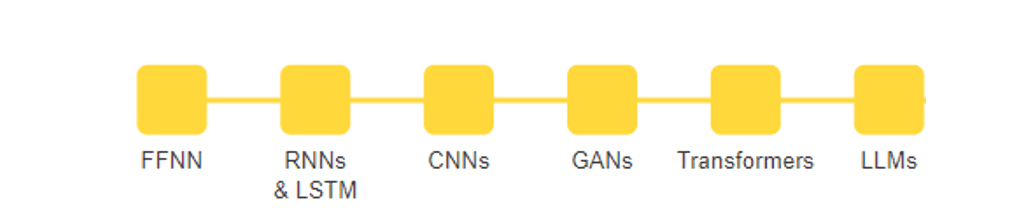
Walkthrough of neural community evolution (picture by creator).
Neural networks, the basic constructing blocks of synthetic intelligence, have revolutionized the way in which we course of info, providing a glimpse into the way forward for expertise. These complicated computational techniques, impressed by the intricacies of the human mind, have change into pivotal in duties starting from picture recognition and pure language understanding to autonomous driving and medical prognosis. As we discover neural networks’ historic evolution, we are going to uncover their exceptional journey of how they’ve advanced to form the fashionable panorama of AI.
How It All Started?
Neural networks, the foundational elements of deep studying, owe their conceptual roots to the intricate organic networks of neurons inside the human mind. This exceptional idea started with a elementary analogy, drawing parallels between organic neurons and computational networks.
This analogy facilities across the mind, which consists of roughly 100 billion neurons. Every neuron maintains about 7,000 synaptic connections with different neurons, creating a posh neural community that underlies human cognitive processes and choice making.
Individually, a organic neuron operates by a sequence of easy electrochemical processes. It receives indicators from different neurons by its dendrites. When these incoming indicators add as much as a sure degree (a predetermined threshold), the neuron switches on and sends an electrochemical sign alongside its axon. This, in flip, impacts the neurons linked to its axon terminals. The important thing factor to notice right here is {that a} neuron’s response is sort of a binary swap: it both fires (prompts) or stays quiet, with none in-between states.
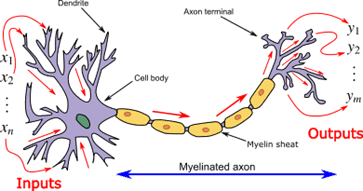
Organic neurons have been the inspiration for synthetic neural networks (picture: Wikipedia).
Synthetic neural networks, as spectacular as they’re, stay a far cry from even remotely approaching the astonishing intricacies and profound complexities of the human mind. Nonetheless, they’ve demonstrated important prowess in addressing issues which might be difficult for standard computer systems however seem intuitive to human cognition. Some examples are picture recognition and predictive analytics primarily based on historic information.
Now that we have explored the foundational rules of how organic neurons perform and their inspiration for synthetic neural networks, let’s journey by the evolution of neural community frameworks which have formed the panorama of synthetic intelligence.
FFNN – Feed Ahead Neural Community
Feed ahead neural networks, sometimes called a multilayer perceptron, are a elementary kind of neural networks, whose operation is deeply rooted within the rules of knowledge circulation, interconnected layers, and parameter optimization.
At their core, FFNNs orchestrate a unidirectional journey of knowledge. All of it begins with the enter layer containing n neurons, the place information is initially ingested. This layer serves because the entry level for the community, performing as a receptor for the enter options that must be processed. From there, the information embarks on a transformative voyage by the community’s hidden layers.
One necessary facet of FFNNs is their linked construction, which implies that every neuron in a layer is intricately linked to each neuron in that layer. This interconnectedness permits the community to carry out computations and seize relationships inside the information. It is like a communication community the place each node performs a task in processing info.
As the information passes by the hidden layers, it undergoes a sequence of calculations. Every neuron in a hidden layer receives inputs from all neurons within the earlier layer, applies a weighted sum to those inputs, provides a bias time period, after which passes the end result by an activation perform (generally ReLU, Sigmoid, or tanH). These mathematical operations allow the community to extract related patterns from the enter, and seize complicated, nonlinear relationships inside information. That is the place FFNNs really excel in comparison with extra shallow ML fashions.
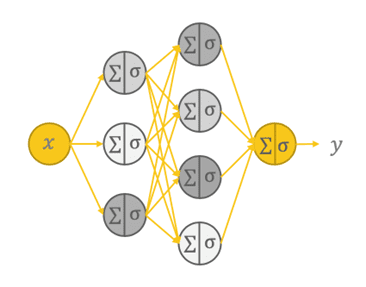
Structure of fully-connected feed-forward neural networks (picture by creator).
Nonetheless, that is not the place it ends. The true energy of FFNNs lies of their capability to adapt. Throughout coaching the community adjusts its weights to reduce the distinction between its predictions and the precise goal values. This iterative course of, usually primarily based on optimization algorithms like gradient descent, is known as backpropagation. Backpropagation empowers FFNNs to really be taught from information and enhance their accuracy in making predictions or classifications.
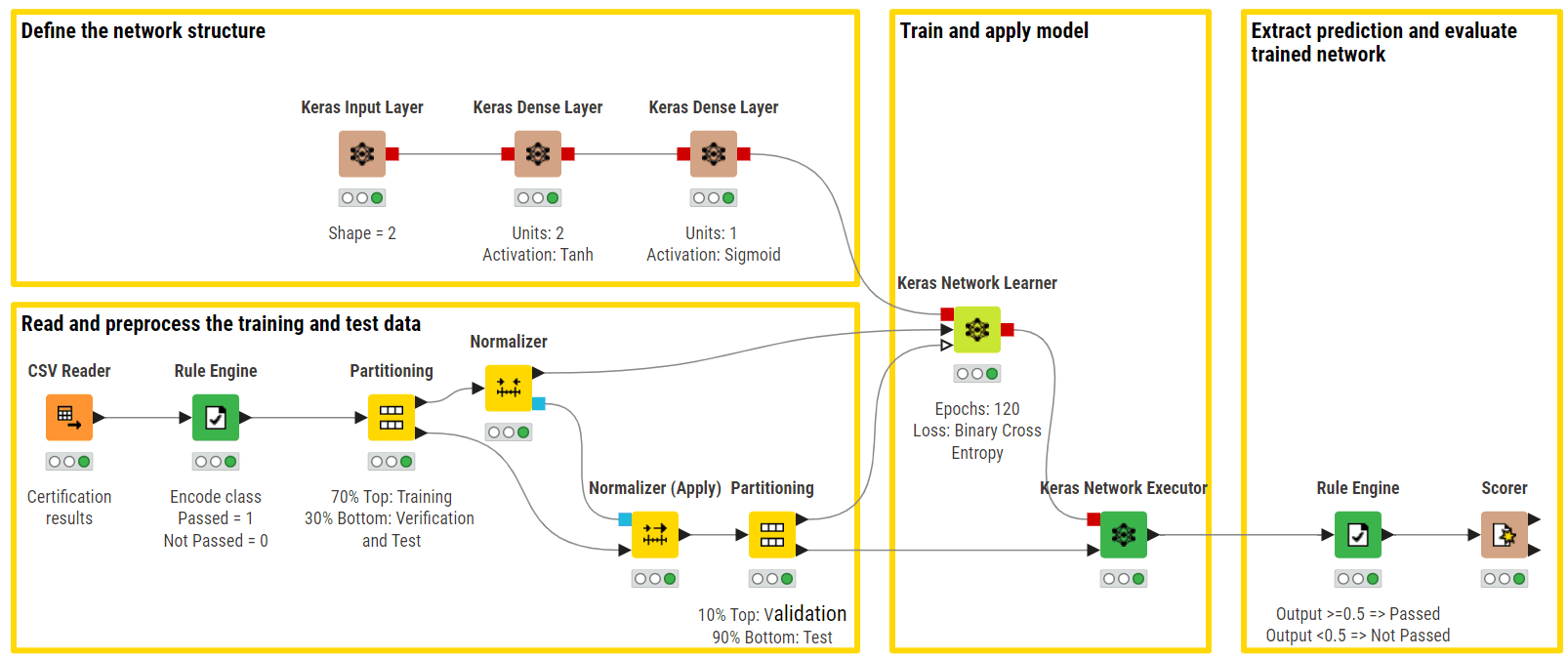
Instance KNIME workflow of FFNN used for the binary classification of certification exams (cross vs fail). Within the higher department, we are able to see the community structure, which is product of an enter layer, a completely linked hidden layer with a tanH activation perform, and an output layer that makes use of a Sigmoid activation perform (picture by creator).
Whereas highly effective and versatile, FFNNs show some related limitations. For instance, they fail to seize sequentiality and temporal/syntactic dependencies within the information –two essential points for duties in language processing and time sequence evaluation. The necessity to overcome these limitations prompted the evolution of a brand new kind of neural community structure. This transition paved the way in which for Recurrent Neural Networks (RNNs), which launched the idea of suggestions loops to raised deal with sequential information.
RNN and LSTM – Recurrent Neural Community and Lengthy Brief-Time period Reminiscence
At their core, RNNs share some similarities with FFNNs. They too are composed of layers of interconnected nodes, processing information to make predictions or classifications. Nonetheless, their key differentiator lies of their capability to deal with sequential information and seize temporal dependencies.
In a FFNN, info flows in a single, unidirectional path from the enter layer to the output layer. That is appropriate for duties the place the order of knowledge would not matter a lot. Nonetheless, when coping with sequences like time sequence information, language, or speech, sustaining context and understanding the order of knowledge is essential. That is the place RNNs shine.
RNNs introduce the idea of suggestions loops. These act as a form of “reminiscence” and permit the community to keep up a hidden state that captures details about earlier inputs and to affect the present enter and output. Whereas conventional neural networks assume that inputs and outputs are impartial of one another, the output of recurrent neural networks depend upon the prior parts inside the sequence. This recurrent connection mechanism makes RNNs significantly match to deal with sequences by “remembering” previous info.
One other distinguishing attribute of recurrent networks is that they share the identical weight parameter inside every layer of the community, and people weights are adjusted leveraging the backpropagation by time (BPTT) algorithm, which is barely totally different from conventional backpropagation as it’s particular to sequence information.
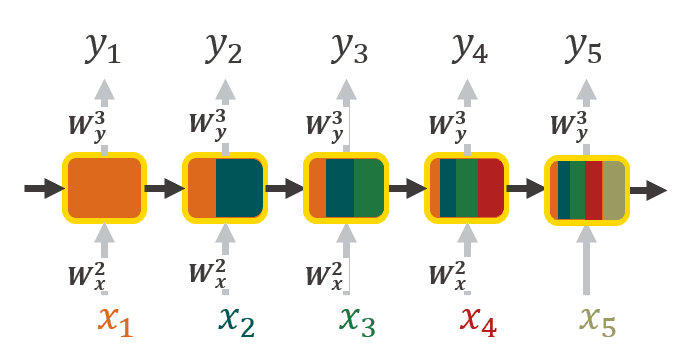
Unrolled illustration of RNNs, the place every enter is enriched with context info coming from earlier inputs. The colour represents the propagation of context info (picture by creator).
Nonetheless, conventional RNNs have their limitations. Whereas in principle they need to be capable to seize long-range dependencies, in actuality they wrestle to take action successfully, and might even undergo from the vanishing gradient drawback, which hinders their capability to be taught and bear in mind info over many time steps.
That is the place Lengthy Brief-Time period Reminiscence (LSTM) models come into play. They’re particularly designed to deal with these points by incorporating three gates into their construction: the Overlook gate, Enter gate, and Output gate.
- Overlook gate: This gate decides which info from the time step ought to be discarded or forgotten. By inspecting the cell state and the present enter, it determines which info is irrelevant for making predictions within the current.
- Enter gate: This gate is chargeable for incorporating info into the cell state. It takes under consideration each the enter and the earlier cell state to resolve what new info ought to be added to boost its state.
- Output gate: This gate concludes what output will likely be generated by the LSTM unit. It considers each the present enter and the up to date cell state to provide an output that may be utilized for predictions or handed on to time steps.

Visible illustration of Lengthy-Brief Time period Reminiscence models (picture by Christopher Olah).
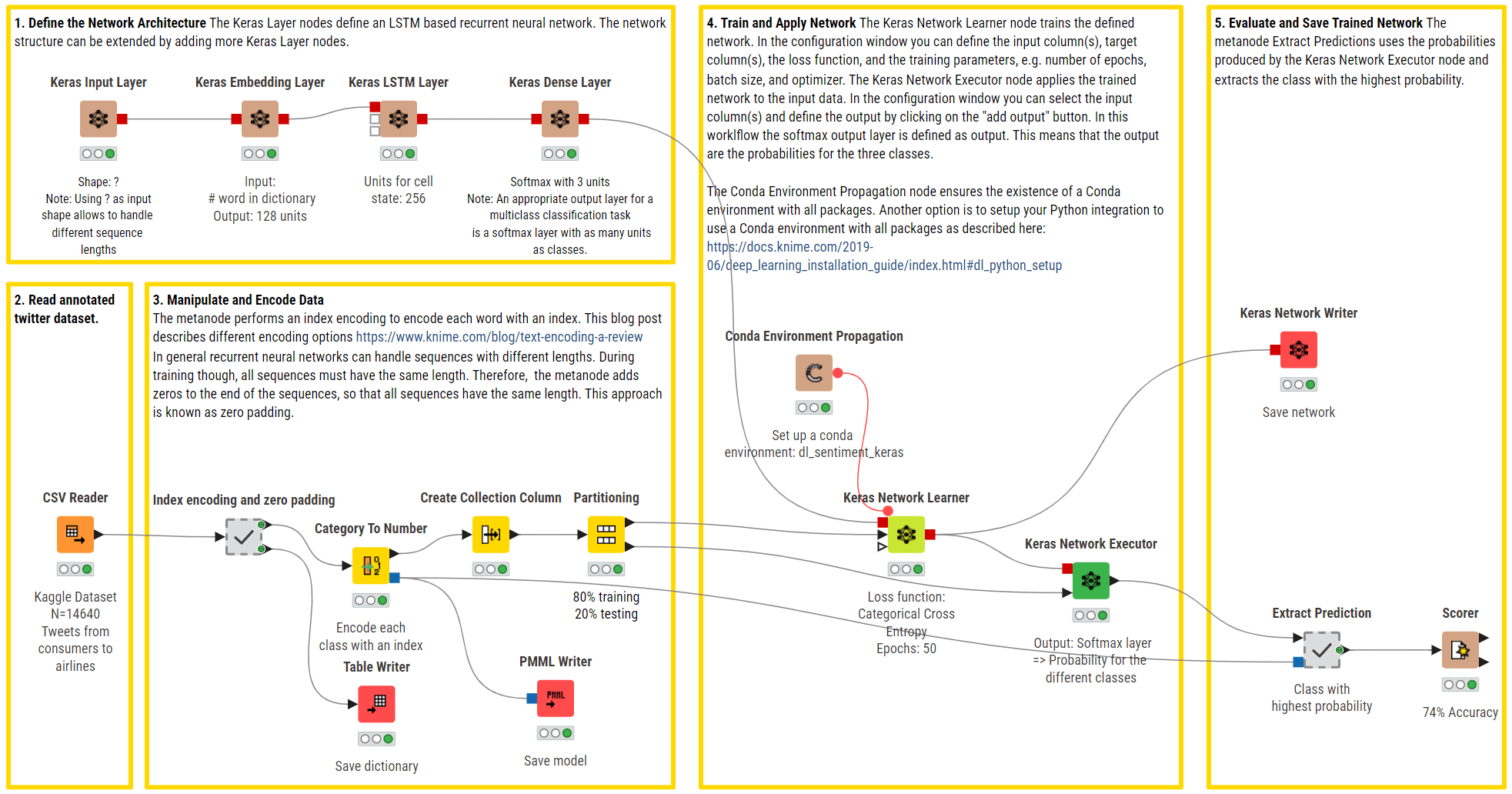
Instance KNIME workflow of RNNs with LSTM models used for a multi-class sentiment prediction (optimistic, destructive, impartial). The higher department defines the community structure utilizing an enter layer to deal with strings of various lengths, an embedding layer, an LSTM layer with a number of models, and a completely linked output layer with a Softmax activation perform to return predictions.
In abstract, RNNs, and particularly LSTM models, are tailor-made for sequential information, permitting them to keep up reminiscence and seize temporal dependencies, which is a important functionality for duties like pure language processing, speech recognition, and time sequence prediction.
As we shift from RNNs capturing sequential dependencies, the evolution continues with Convolutional Neural Networks (CNNs). Not like RNNs, CNNs excel at spatial function extraction from structured grid-like information, making them ultimate for picture and sample recognition duties. This transition displays the varied functions of neural networks throughout totally different information varieties and constructions.
CNN – Convolutional Neural Community
CNNs are a particular breed of neural networks, significantly well-suited for processing picture information, corresponding to 2D photographs and even 3D video information. Their structure depends on a multilayered feed-forward neural community with at the least one convolutional layer.
What makes CNNs stand out is their community connectivity and strategy to function extraction, which permits them to routinely determine related patterns within the information. Not like conventional FFNNs, which join each neuron in a single layer to each neuron within the subsequent, CNNs make use of a sliding window referred to as a kernel or filter. This sliding window scans throughout the enter information and is particularly highly effective for duties the place spatial relationships matter, like figuring out objects in photographs or monitoring movement in movies. Because the kernel is moved throughout the picture, a convolution operation is carried out between the kernel and the pixel values (from a strictly mathematical standpoint, this operation is a cross correlation), and a nonlinear activation perform, often ReLU, is utilized. This produces a excessive worth if the function is within the picture patch and a small worth if it isn’t.
Along with the kernel, the addition and fine-tuning of hyperparameters, corresponding to stride (i.e., the variety of pixels by which we slide the kernel) and dilation charge (i.e., the areas between every kernel cell), permits the community to deal with particular options, recognizing patterns and particulars in particular areas with out contemplating all the enter directly.
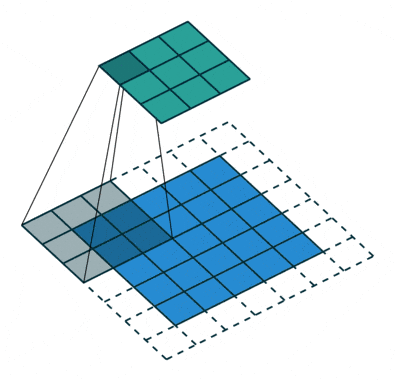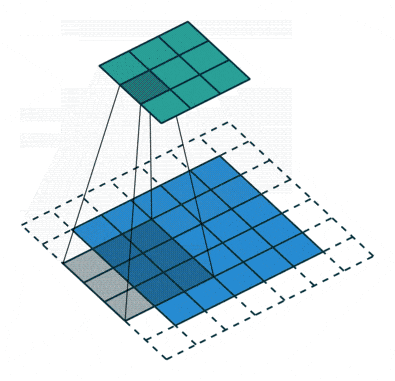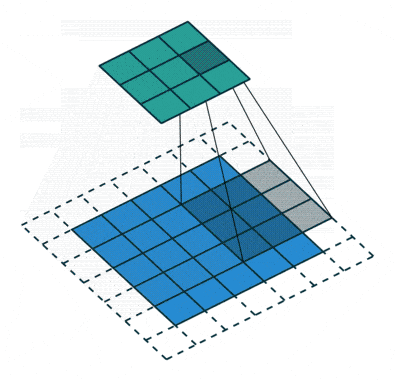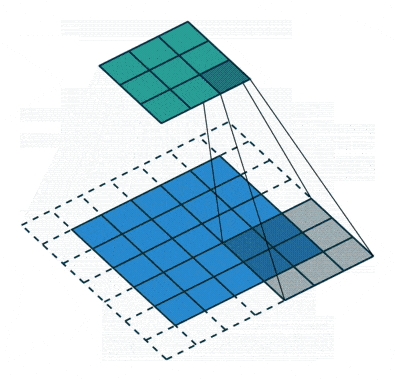
Convolution operation with stride size = 2 (GIF by Sumit Saha).
Some kernels could specialise in detecting edges or corners, whereas others is perhaps tuned to acknowledge extra complicated objects like cats, canine, or road indicators inside a picture. By stacking collectively a number of convolutional and pooling layers, CNNs construct a hierarchical illustration of the enter, regularly abstracting options from low-level to high-level, simply as our brains course of visible info.
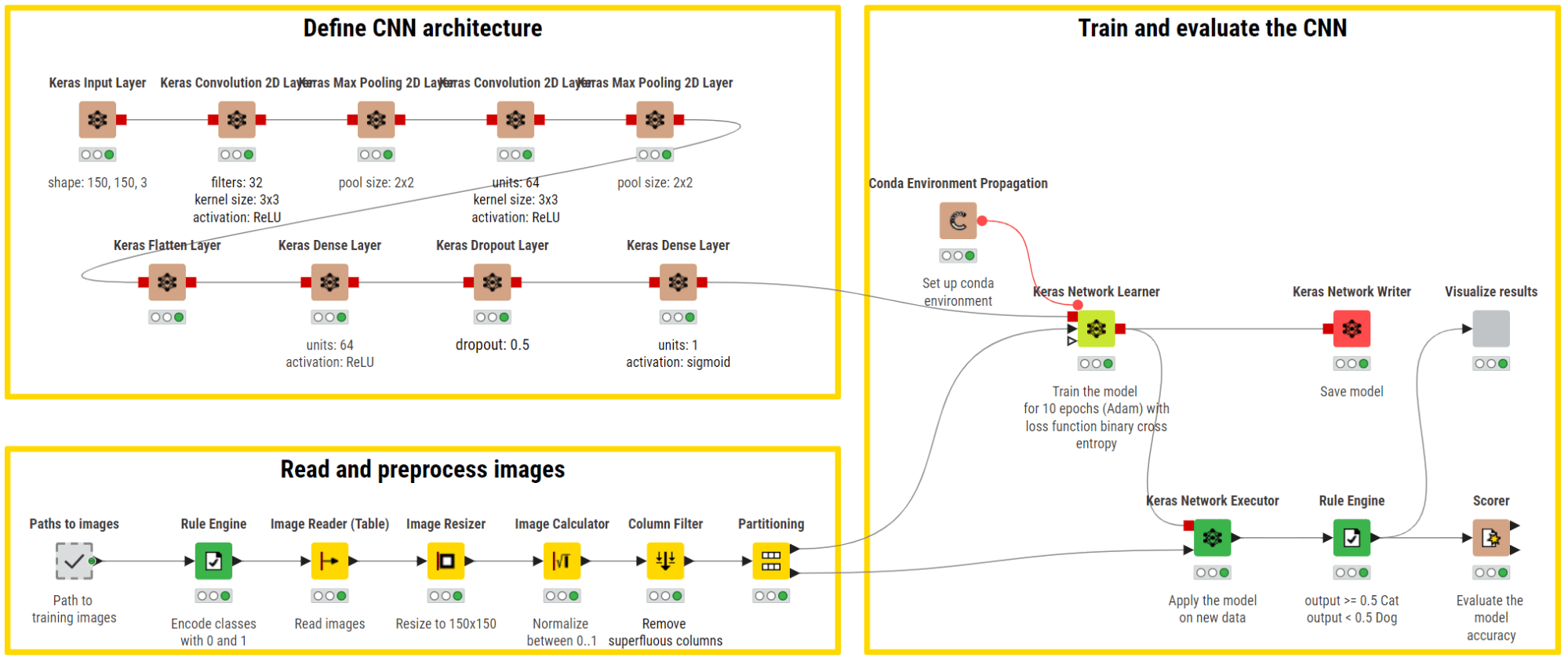
Instance KNIME workflow of CNN for binary picture classification (cats vs canine). The higher department defines the community structure utilizing a sequence of convolutional layers and max pooling layers for automated function extraction from photographs. A flatten layer is then used to organize the extracted options as a unidimensional enter for the FFNN to carry out a binary classification.
Whereas CNNs excel at function extraction and have revolutionized laptop imaginative and prescient duties, they act as passive observers, for they don’t seem to be designed to generate new information or content material. This isn’t an inherent limitation of the community per se however having a strong engine and no gas makes a quick automobile ineffective. Certainly, actual and significant picture and video information are typically laborious and costly to gather and have a tendency to face copyright and information privateness restrictions. This constraint led to the event of a novel paradigm that builds on CNNs however marks a leap from picture classification to artistic synthesis: Generative Adversarial Networks (GANs).
GAN – Generative Adversarial Networks
GANs are a selected household of neural networks whose major, however not the one, objective is to provide artificial information that carefully mimics a given dataset of actual information. Not like most neural networks, GANs’ ingenious architectural design consisting of two core fashions:
- Generator mannequin: The primary participant on this neural community duet is the generator mannequin. This element is tasked with a captivating mission: given random noise or enter vectors, it strives to create synthetic samples which might be as near resembling actual samples as doable. Think about it as an artwork forger, trying to craft work which might be indistinguishable from masterpieces.
- Discriminator mannequin: Enjoying the adversary function is the discriminator mannequin. Its job is to distinguish between the generated samples produced by the generator and the genuine samples from the unique dataset. Consider it as an artwork connoisseur, attempting to identify the forgeries among the many real artworks.
Now, this is the place the magic occurs: GANs interact in a steady, adversarial dance. The generator goals to enhance its artistry, regularly fine-tuning its creations to change into extra convincing. In the meantime, the discriminator turns into a sharper detective, honing its capability to inform the true from the faux.
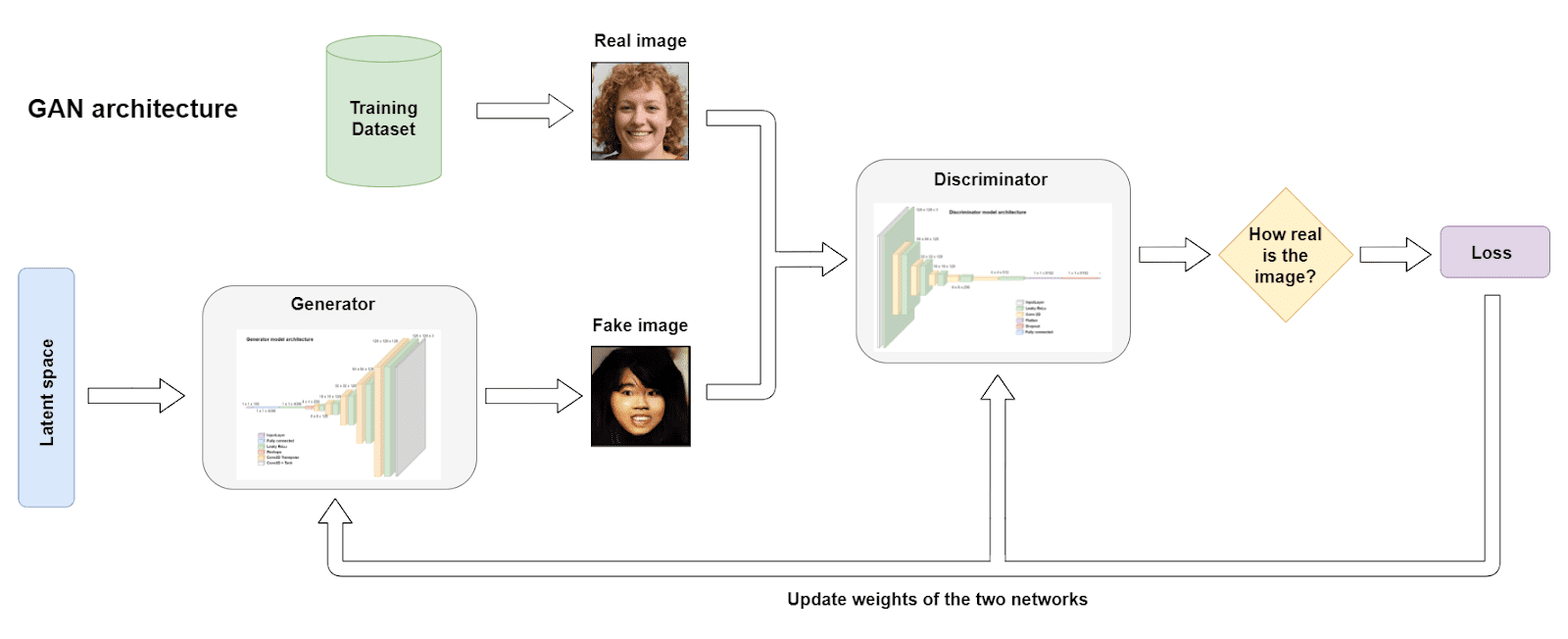
GAN structure (picture by creator).
As coaching progresses, this dynamic interaction between the generator and discriminator results in a captivating final result. The generator strives to generate samples which might be so sensible that even the discriminator cannot inform them aside from the real ones. This competitors drives each elements to refine their skills repeatedly.
The end result? A generator that turns into astonishingly adept at producing information that seems genuine, be it photographs, music, or textual content. This functionality has led to exceptional functions in varied fields, together with picture synthesis, information augmentation, image-to-image translation, and picture modifying.
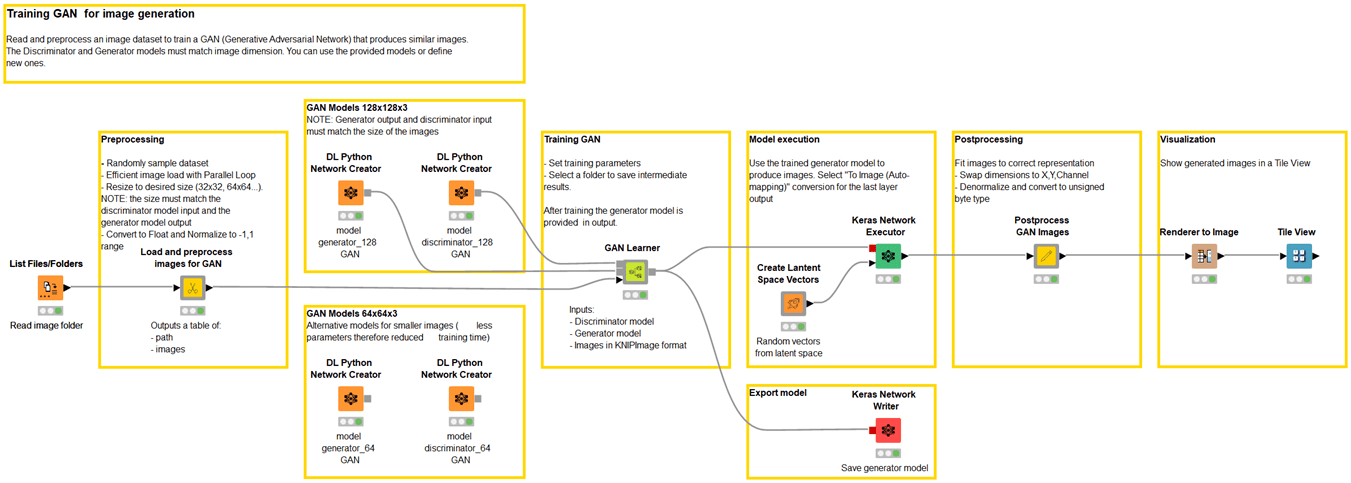
Instance KNIME workflow of GANs for the era of artificial photographs (i.e., animals, human faces and Simpson characters).
GANs pioneered sensible picture and video content material creation by pitting a generator in opposition to a discriminator. Extending the necessity for creativity and superior operations from picture to sequential information, fashions for extra refined pure language understanding, machine translation, and textual content era have been launched. This initiated the event of Transformers, a exceptional deep neural community structure that not solely outperformed earlier architectures by successfully capturing long-range language dependencies and semantic context, but additionally grew to become the undisputed basis of the newest AI-driven functions.
Transformers
Developed in 2017, Transformers boast a singular function that permits them to switch conventional recurrent layers: a self-attention mechanism that permits them to mannequin intricate relationships between all phrases in a doc, no matter their place. This makes Transformers glorious at tackling the problem of long-range dependencies in pure language. Transformer architectures encompass two predominant constructing blocks:
- Encoder. Right here the enter sequence is embedded into vectors after which is uncovered to the self-attention mechanism. The latter computes consideration scores for every token, figuring out its significance in relation to others. These scores are used to create weighted sums, that are fed right into a FFNN to generate context-aware representations for every token. A number of encoder layers repeat this course of, enhancing the mannequin’s capability to seize hierarchical and contextual info.
- Decoder. This block is chargeable for producing output sequences and follows an identical course of to that of the encoder. It is ready to place the right deal with and perceive the encoder’s output and its personal previous tokens throughout every step, guaranteeing correct era by contemplating each enter context and beforehand generated output.
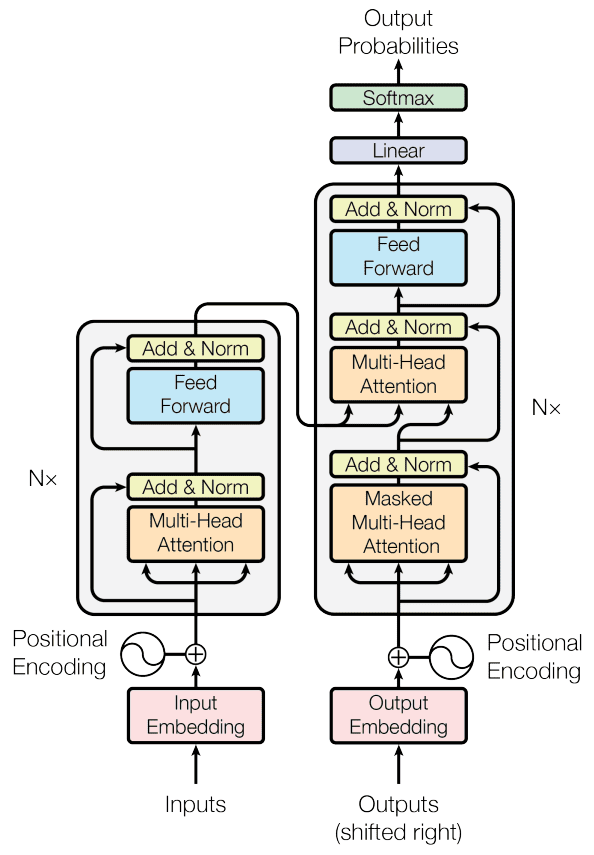
Transformer mannequin structure (picture by: Vaswani et al., 2017).
Contemplate this sentence: “I arrived on the financial institution after crossing the river”. The phrase “financial institution” can have two meanings –both a monetary establishment or the sting of a river. Here is the place transformers shine. They’ll swiftly deal with the phrase “river” to disambiguate “financial institution” by evaluating “financial institution” to each different phrase within the sentence and assigning consideration scores. These scores decide the affect of every phrase on the subsequent illustration of “financial institution”. On this case, “river” will get a better rating, successfully clarifying the meant that means.
To work that nicely, Transformers depend on hundreds of thousands of trainable parameters, require giant corpora of texts and complex coaching methods. One notable coaching strategy employed with Transformers is masked language modeling (MLM). Throughout coaching, particular tokens inside the enter sequence are randomly masked, and the mannequin’s goal is to foretell these masked tokens precisely. This technique encourages the mannequin to know contextual relationships between phrases as a result of it should depend on the encompassing phrases to make correct predictions. This strategy, popularized by the BERT mannequin, has been instrumental in reaching state-of-the-art leads to varied NLP duties.
An alternative choice to MLM for Transformers is autoregressive modeling. On this methodology, the mannequin is educated to generate one phrase at a time whereas conditioning on beforehand generated phrases. Autoregressive fashions like GPT (Generative Pre-trained Transformer) observe this technique and excel in duties the place the purpose is to foretell unidirectionally the subsequent most fitted phrase, corresponding to free textual content era, query answering and textual content completion.
Moreover, to compensate for the necessity for intensive textual content sources, Transformers excel in parallelization, that means they’ll course of information throughout coaching sooner than conventional sequential approaches like RNNs or LSTM models. This environment friendly computation reduces coaching time and has led to groundbreaking functions in pure language processing, machine translation, and extra.
A pivotal Transformer mannequin developed by Google in 2018 that made a considerable affect is BERT (Bidirectional Encoder Representations from Transformers). BERT relied on MLM coaching and launched the idea of bidirectional context, that means it considers each the left and proper context of a phrase when predicting the masked token. This bidirectional strategy considerably enhanced the mannequin’s understanding of phrase meanings and contextual nuances, establishing new benchmarks for pure language understanding and a wide selection of downstream NLP duties.
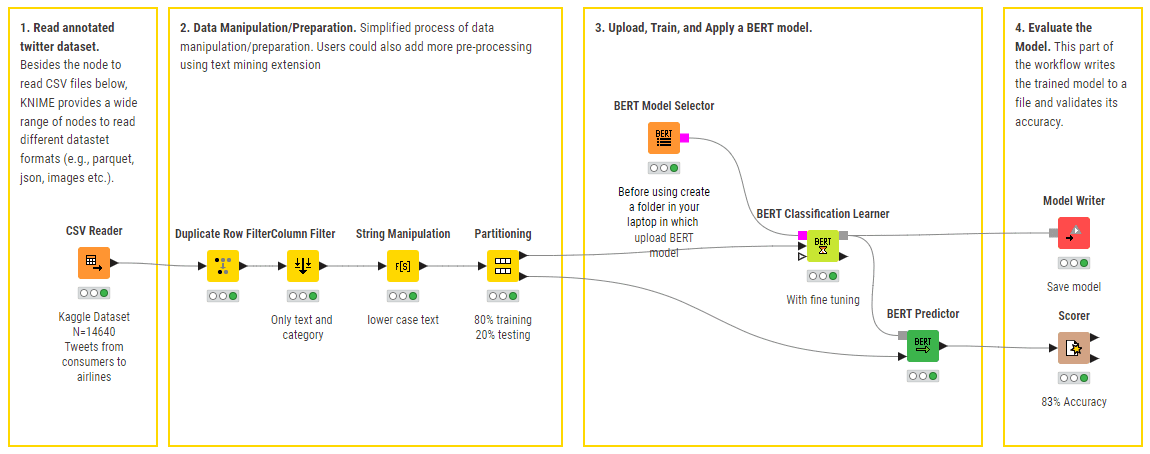
Instance KNIME workflow of BERT for multi-class sentiment prediction (optimistic, destructive, impartial). Minimal preprocessing is carried out and the pretrained BERT mannequin with fine-tuning is leveraged.
On the heels of Transformers that launched highly effective self-attention mechanisms, the rising demand for versatility in functions and performing complicated pure language duties, corresponding to doc summarization, textual content modifying, or code era, necessitated the event of giant language fashions. These fashions make use of deep neural networks with billions of parameters to excel in such duties and meet the evolving necessities of the information analytics business.
LLM – Giant Language Mannequin
Giant language fashions (LLMs) are a revolutionary class of multi-purpose and multi-modal (accepting picture, audio and textual content inputs) deep neural networks which have garnered important consideration in recent times. The adjective giant stems from their huge measurement, as they embody billions of trainable parameters. A number of the most well-known examples embrace OpenAI’s ChatGTP, Google’s Bard or Meta’s LLaMa.
What units LLMs aside is their unparalleled capability and suppleness to course of and generate human-like textual content. They excel in pure language understanding and era duties, starting from textual content completion and translation to query answering and content material summarization. The important thing to their success lies of their intensive coaching on large textual content corpora, permitting them to seize a wealthy understanding of language nuances, context, and semantics.
These fashions make use of a deep neural structure with a number of layers of self-attention mechanisms, enabling them to weigh the significance of various phrases and phrases in a given context. This dynamic adaptability makes them exceptionally proficient in processing inputs of varied varieties, comprehending complicated language constructions, and producing outputs primarily based on human-defined prompts.
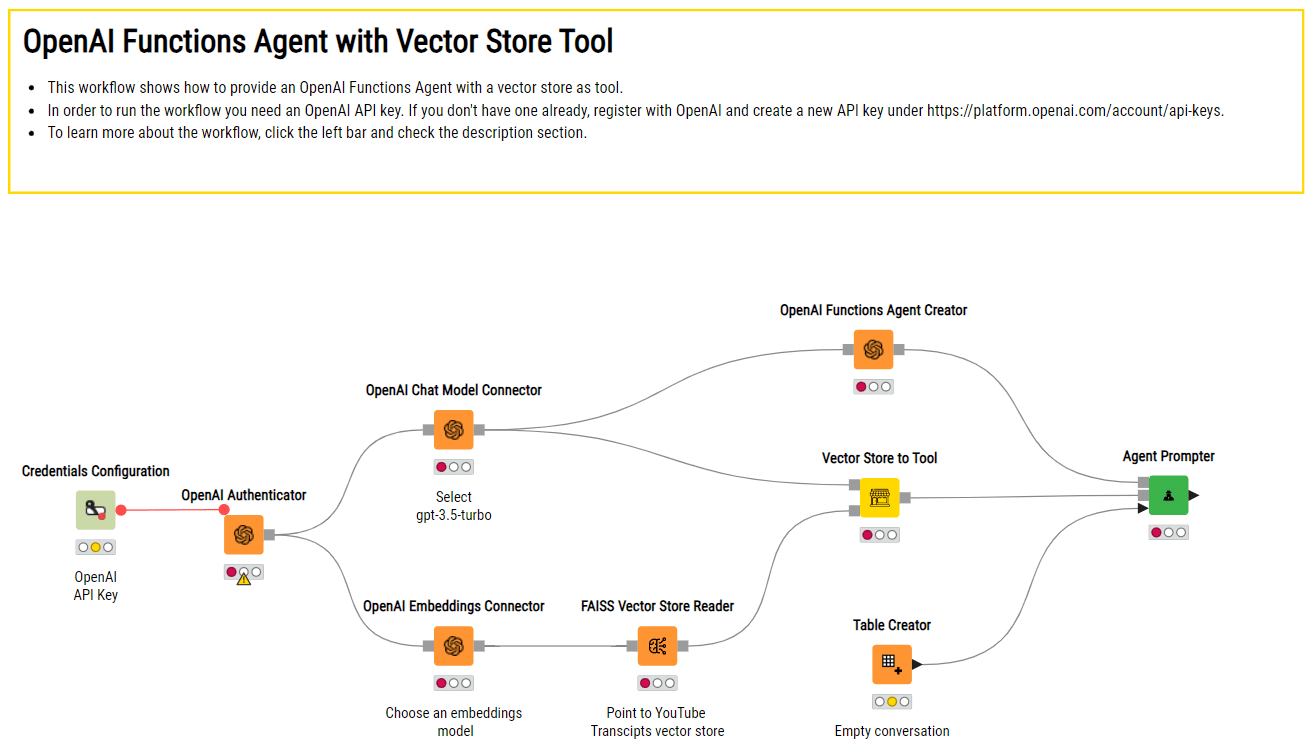
Instance KNIME workflow of making an AI assistant that depends on OpenAI’s ChatGPT and a vector retailer with customized paperwork to reply domain-specific questions.
LLMs have paved the way in which for a mess of functions throughout varied industries, from healthcare and finance to leisure and customer support. They’ve even sparked new frontiers in artistic writing and storytelling.
Nonetheless, their huge measurement, resource-intensive coaching processes and potential copyright infringements for generated content material have additionally raised issues about moral utilization, environmental affect, and accessibility. Lastly, whereas more and more enhanced, LLMs could comprise some severe flaws, corresponding to “hallucinating” incorrect info, being biased, gullible, or persuaded into creating poisonous content material.
Is there an Finish?
The evolution of neural networks, from their humble beginnings to the rebellion of huge language fashions, raises a profound philosophical query: Will this journey ever come to an finish?
The trajectory of expertise has all the time been marked by relentless development. Every milestone solely serves as a stepping stone to the subsequent innovation. As we attempt to create machines that may replicate human cognition and understanding, it is tempting to ponder whether or not there’s an final vacation spot, a degree the place we are saying, “That is it; we have reached the head.”
Nonetheless, the essence of human curiosity and the boundless complexities of the pure world recommend in any other case. Simply as our understanding of the universe regularly deepens, the search to develop extra clever, succesful, and moral neural networks could also be an infinite journey.Walkthrough of neural community evolution (picture by creator).
Neural networks, the basic constructing blocks of synthetic intelligence, have revolutionized the way in which we course of info, providing a glimpse into the way forward for expertise. These complicated computational techniques, impressed by the intricacies of the human mind, have change into pivotal in duties starting from picture recognition and pure language understanding to autonomous driving and medical prognosis. As we discover neural networks’ historic evolution, we are going to uncover their exceptional journey of how they’ve advanced to form the fashionable panorama of AI.
How It All Started?
Neural networks, the foundational elements of deep studying, owe their conceptual roots to the intricate organic networks of neurons inside the human mind. This exceptional idea started with a elementary analogy, drawing parallels between organic neurons and computational networks.
This analogy facilities across the mind, which consists of roughly 100 billion neurons. Every neuron maintains about 7,000 synaptic connections with different neurons, creating a posh neural community that underlies human cognitive processes and choice making.
Individually, a organic neuron operates by a sequence of easy electrochemical processes. It receives indicators from different neurons by its dendrites. When these incoming indicators add as much as a sure degree (a predetermined threshold), the neuron switches on and sends an electrochemical sign alongside its axon. This, in flip, impacts the neurons linked to its axon terminals. The important thing factor to notice right here is {that a} neuron’s response is sort of a binary swap: it both fires (prompts) or stays quiet, with none in-between states.
Organic neurons have been the inspiration for synthetic neural networks (picture: Wikipedia).
Synthetic neural networks, as spectacular as they’re, stay a far cry from even remotely approaching the astonishing intricacies and profound complexities of the human mind. Nonetheless, they’ve demonstrated important prowess in addressing issues which might be difficult for standard computer systems however seem intuitive to human cognition. Some examples are picture recognition and predictive analytics primarily based on historic information.
Now that we have explored the foundational rules of how organic neurons perform and their inspiration for synthetic neural networks, let’s journey by the evolution of neural community frameworks which have formed the panorama of synthetic intelligence.
FFNN – Feed Ahead Neural Community
Feed ahead neural networks, sometimes called a multilayer perceptron, are a elementary kind of neural networks, whose operation is deeply rooted within the rules of knowledge circulation, interconnected layers, and parameter optimization.
At their core, FFNNs orchestrate a unidirectional journey of knowledge. All of it begins with the enter layer containing n neurons, the place information is initially ingested. This layer serves because the entry level for the community, performing as a receptor for the enter options that must be processed. From there, the information embarks on a transformative voyage by the community’s hidden layers.
One necessary facet of FFNNs is their linked construction, which implies that every neuron in a layer is intricately linked to each neuron in that layer. This interconnectedness permits the community to carry out computations and seize relationships inside the information. It is like a communication community the place each node performs a task in processing info.
As the information passes by the hidden layers, it undergoes a sequence of calculations. Every neuron in a hidden layer receives inputs from all neurons within the earlier layer, applies a weighted sum to those inputs, provides a bias time period, after which passes the end result by an activation perform (generally ReLU, Sigmoid, or tanH). These mathematical operations allow the community to extract related patterns from the enter, and seize complicated, nonlinear relationships inside information. That is the place FFNNs really excel in comparison with extra shallow ML fashions.
Structure of fully-connected feed-forward neural networks (picture by creator).
Nonetheless, that is not the place it ends. The true energy of FFNNs lies of their capability to adapt. Throughout coaching the community adjusts its weights to reduce the distinction between its predictions and the precise goal values. This iterative course of, usually primarily based on optimization algorithms like gradient descent, is known as backpropagation. Backpropagation empowers FFNNs to really be taught from information and enhance their accuracy in making predictions or classifications.
Instance KNIME workflow of FFNN used for the binary classification of certification exams (cross vs fail). Within the higher department, we are able to see the community structure, which is product of an enter layer, a completely linked hidden layer with a tanH activation perform, and an output layer that makes use of a Sigmoid activation perform (picture by creator).
Whereas highly effective and versatile, FFNNs show some related limitations. For instance, they fail to seize sequentiality and temporal/syntactic dependencies within the information –two essential points for duties in language processing and time sequence evaluation. The necessity to overcome these limitations prompted the evolution of a brand new kind of neural community structure. This transition paved the way in which for Recurrent Neural Networks (RNNs), which launched the idea of suggestions loops to raised deal with sequential information.
RNN and LSTM – Recurrent Neural Community and Lengthy Brief-Time period Reminiscence
At their core, RNNs share some similarities with FFNNs. They too are composed of layers of interconnected nodes, processing information to make predictions or classifications. Nonetheless, their key differentiator lies of their capability to deal with sequential information and seize temporal dependencies.
In a FFNN, info flows in a single, unidirectional path from the enter layer to the output layer. That is appropriate for duties the place the order of knowledge would not matter a lot. Nonetheless, when coping with sequences like time sequence information, language, or speech, sustaining context and understanding the order of knowledge is essential. That is the place RNNs shine.
RNNs introduce the idea of suggestions loops. These act as a form of “reminiscence” and permit the community to keep up a hidden state that captures details about earlier inputs and to affect the present enter and output. Whereas conventional neural networks assume that inputs and outputs are impartial of one another, the output of recurrent neural networks depend upon the prior parts inside the sequence. This recurrent connection mechanism makes RNNs significantly match to deal with sequences by “remembering” previous info.
One other distinguishing attribute of recurrent networks is that they share the identical weight parameter inside every layer of the community, and people weights are adjusted leveraging the backpropagation by time (BPTT) algorithm, which is barely totally different from conventional backpropagation as it’s particular to sequence information.
Unrolled illustration of RNNs, the place every enter is enriched with context info coming from earlier inputs. The colour represents the propagation of context info (picture by creator).
Nonetheless, conventional RNNs have their limitations. Whereas in principle they need to be capable to seize long-range dependencies, in actuality they wrestle to take action successfully, and might even undergo from the vanishing gradient drawback, which hinders their capability to be taught and bear in mind info over many time steps.
That is the place Lengthy Brief-Time period Reminiscence (LSTM) models come into play. They’re particularly designed to deal with these points by incorporating three gates into their construction: the Overlook gate, Enter gate, and Output gate.
- Overlook gate: This gate decides which info from the time step ought to be discarded or forgotten. By inspecting the cell state and the present enter, it determines which info is irrelevant for making predictions within the current.
- Enter gate: This gate is chargeable for incorporating info into the cell state. It takes under consideration each the enter and the earlier cell state to resolve what new info ought to be added to boost its state.
- Output gate: This gate concludes what output will likely be generated by the LSTM unit. It considers each the present enter and the up to date cell state to provide an output that may be utilized for predictions or handed on to time steps.
Visible illustration of Lengthy-Brief Time period Reminiscence models (picture by Christopher Olah).
Instance KNIME workflow of RNNs with LSTM models used for a multi-class sentiment prediction (optimistic, destructive, impartial). The higher department defines the community structure utilizing an enter layer to deal with strings of various lengths, an embedding layer, an LSTM layer with a number of models, and a completely linked output layer with a Softmax activation perform to return predictions.
In abstract, RNNs, and particularly LSTM models, are tailor-made for sequential information, permitting them to keep up reminiscence and seize temporal dependencies, which is a important functionality for duties like pure language processing, speech recognition, and time sequence prediction.
As we shift from RNNs capturing sequential dependencies, the evolution continues with Convolutional Neural Networks (CNNs). Not like RNNs, CNNs excel at spatial function extraction from structured grid-like information, making them ultimate for picture and sample recognition duties. This transition displays the varied functions of neural networks throughout totally different information varieties and constructions.
CNN – Convolutional Neural Community
CNNs are a particular breed of neural networks, significantly well-suited for processing picture information, corresponding to 2D photographs and even 3D video information. Their structure depends on a multilayered feed-forward neural community with at the least one convolutional layer.
What makes CNNs stand out is their community connectivity and strategy to function extraction, which permits them to routinely determine related patterns within the information. Not like conventional FFNNs, which join each neuron in a single layer to each neuron within the subsequent, CNNs make use of a sliding window referred to as a kernel or filter. This sliding window scans throughout the enter information and is particularly highly effective for duties the place spatial relationships matter, like figuring out objects in photographs or monitoring movement in movies. Because the kernel is moved throughout the picture, a convolution operation is carried out between the kernel and the pixel values (from a strictly mathematical standpoint, this operation is a cross correlation), and a nonlinear activation perform, often ReLU, is utilized. This produces a excessive worth if the function is within the picture patch and a small worth if it isn’t.
Along with the kernel, the addition and fine-tuning of hyperparameters, corresponding to stride (i.e., the variety of pixels by which we slide the kernel) and dilation charge (i.e., the areas between every kernel cell), permits the community to deal with particular options, recognizing patterns and particulars in particular areas with out contemplating all the enter directly.
Convolution operation with stride size = 2 (GIF by Sumit Saha).
Some kernels could specialise in detecting edges or corners, whereas others is perhaps tuned to acknowledge extra complicated objects like cats, canine, or road indicators inside a picture. By stacking collectively a number of convolutional and pooling layers, CNNs construct a hierarchical illustration of the enter, regularly abstracting options from low-level to high-level, simply as our brains course of visible info.
Instance KNIME workflow of CNN for binary picture classification (cats vs canine). The higher department defines the community structure utilizing a sequence of convolutional layers and max pooling layers for automated function extraction from photographs. A flatten layer is then used to organize the extracted options as a unidimensional enter for the FFNN to carry out a binary classification.
Whereas CNNs excel at function extraction and have revolutionized laptop imaginative and prescient duties, they act as passive observers, for they don’t seem to be designed to generate new information or content material. This isn’t an inherent limitation of the community per se however having a strong engine and no gas makes a quick automobile ineffective. Certainly, actual and significant picture and video information are typically laborious and costly to gather and have a tendency to face copyright and information privateness restrictions. This constraint led to the event of a novel paradigm that builds on CNNs however marks a leap from picture classification to artistic synthesis: Generative Adversarial Networks (GANs).
GAN – Generative Adversarial Networks
GANs are a selected household of neural networks whose major, however not the one, objective is to provide artificial information that carefully mimics a given dataset of actual information. Not like most neural networks, GANs’ ingenious architectural design consisting of two core fashions:
- Generator mannequin: The primary participant on this neural community duet is the generator mannequin. This element is tasked with a captivating mission: given random noise or enter vectors, it strives to create synthetic samples which might be as near resembling actual samples as doable. Think about it as an artwork forger, trying to craft work which might be indistinguishable from masterpieces.
- Discriminator mannequin: Enjoying the adversary function is the discriminator mannequin. Its job is to distinguish between the generated samples produced by the generator and the genuine samples from the unique dataset. Consider it as an artwork connoisseur, attempting to identify the forgeries among the many real artworks.
Now, this is the place the magic occurs: GANs interact in a steady, adversarial dance. The generator goals to enhance its artistry, regularly fine-tuning its creations to change into extra convincing. In the meantime, the discriminator turns into a sharper detective, honing its capability to inform the true from the faux.
GAN structure (picture by creator).
As coaching progresses, this dynamic interaction between the generator and discriminator results in a captivating final result. The generator strives to generate samples which might be so sensible that even the discriminator cannot inform them aside from the real ones. This competitors drives each elements to refine their skills repeatedly.
The end result? A generator that turns into astonishingly adept at producing information that seems genuine, be it photographs, music, or textual content. This functionality has led to exceptional functions in varied fields, together with picture synthesis, information augmentation, image-to-image translation, and picture modifying.
Instance KNIME workflow of GANs for the era of artificial photographs (i.e., animals, human faces and Simpson characters).
GANs pioneered sensible picture and video content material creation by pitting a generator in opposition to a discriminator. Extending the necessity for creativity and superior operations from picture to sequential information, fashions for extra refined pure language understanding, machine translation, and textual content era have been launched. This initiated the event of Transformers, a exceptional deep neural community structure that not solely outperformed earlier architectures by successfully capturing long-range language dependencies and semantic context, but additionally grew to become the undisputed basis of the newest AI-driven functions.
Transformers
Developed in 2017, Transformers boast a singular function that permits them to switch conventional recurrent layers: a self-attention mechanism that permits them to mannequin intricate relationships between all phrases in a doc, no matter their place. This makes Transformers glorious at tackling the problem of long-range dependencies in pure language. Transformer architectures encompass two predominant constructing blocks:
- Encoder. Right here the enter sequence is embedded into vectors after which is uncovered to the self-attention mechanism. The latter computes consideration scores for every token, figuring out its significance in relation to others. These scores are used to create weighted sums, that are fed right into a FFNN to generate context-aware representations for every token. A number of encoder layers repeat this course of, enhancing the mannequin’s capability to seize hierarchical and contextual info.
- Decoder. This block is chargeable for producing output sequences and follows an identical course of to that of the encoder. It is ready to place the right deal with and perceive the encoder’s output and its personal previous tokens throughout every step, guaranteeing correct era by contemplating each enter context and beforehand generated output.
Transformer mannequin structure (picture by: Vaswani et al., 2017).
Contemplate this sentence: “I arrived on the financial institution after crossing the river”. The phrase “financial institution” can have two meanings –both a monetary establishment or the sting of a river. Here is the place transformers shine. They’ll swiftly deal with the phrase “river” to disambiguate “financial institution” by evaluating “financial institution” to each different phrase within the sentence and assigning consideration scores. These scores decide the affect of every phrase on the subsequent illustration of “financial institution”. On this case, “river” will get a better rating, successfully clarifying the meant that means.
To work that nicely, Transformers depend on hundreds of thousands of trainable parameters, require giant corpora of texts and complex coaching methods. One notable coaching strategy employed with Transformers is masked language modeling (MLM). Throughout coaching, particular tokens inside the enter sequence are randomly masked, and the mannequin’s goal is to foretell these masked tokens precisely. This technique encourages the mannequin to know contextual relationships between phrases as a result of it should depend on the encompassing phrases to make correct predictions. This strategy, popularized by the BERT mannequin, has been instrumental in reaching state-of-the-art leads to varied NLP duties.
An alternative choice to MLM for Transformers is autoregressive modeling. On this methodology, the mannequin is educated to generate one phrase at a time whereas conditioning on beforehand generated phrases. Autoregressive fashions like GPT (Generative Pre-trained Transformer) observe this technique and excel in duties the place the purpose is to foretell unidirectionally the subsequent most fitted phrase, corresponding to free textual content era, query answering and textual content completion.
Moreover, to compensate for the necessity for intensive textual content sources, Transformers excel in parallelization, that means they’ll course of information throughout coaching sooner than conventional sequential approaches like RNNs or LSTM models. This environment friendly computation reduces coaching time and has led to groundbreaking functions in pure language processing, machine translation, and extra.
A pivotal Transformer mannequin developed by Google in 2018 that made a considerable affect is BERT (Bidirectional Encoder Representations from Transformers). BERT relied on MLM coaching and launched the idea of bidirectional context, that means it considers each the left and proper context of a phrase when predicting the masked token. This bidirectional strategy considerably enhanced the mannequin’s understanding of phrase meanings and contextual nuances, establishing new benchmarks for pure language understanding and a wide selection of downstream NLP duties.
Instance KNIME workflow of BERT for multi-class sentiment prediction (optimistic, destructive, impartial). Minimal preprocessing is carried out and the pretrained BERT mannequin with fine-tuning is leveraged.
On the heels of Transformers that launched highly effective self-attention mechanisms, the rising demand for versatility in functions and performing complicated pure language duties, corresponding to doc summarization, textual content modifying, or code era, necessitated the event of giant language fashions. These fashions make use of deep neural networks with billions of parameters to excel in such duties and meet the evolving necessities of the information analytics business.
LLM – Giant Language Mannequin
Giant language fashions (LLMs) are a revolutionary class of multi-purpose and multi-modal (accepting picture, audio and textual content inputs) deep neural networks which have garnered important consideration in recent times. The adjective giant stems from their huge measurement, as they embody billions of trainable parameters. A number of the most well-known examples embrace OpenAI’s ChatGTP, Google’s Bard or Meta’s LLaMa.
What units LLMs aside is their unparalleled capability and suppleness to course of and generate human-like textual content. They excel in pure language understanding and era duties, starting from textual content completion and translation to query answering and content material summarization. The important thing to their success lies of their intensive coaching on large textual content corpora, permitting them to seize a wealthy understanding of language nuances, context, and semantics.
These fashions make use of a deep neural structure with a number of layers of self-attention mechanisms, enabling them to weigh the significance of various phrases and phrases in a given context. This dynamic adaptability makes them exceptionally proficient in processing inputs of varied varieties, comprehending complicated language constructions, and producing outputs primarily based on human-defined prompts.
Instance KNIME workflow of making an AI assistant that depends on OpenAI’s ChatGPT and a vector retailer with customized paperwork to reply domain-specific questions.
LLMs have paved the way in which for a mess of functions throughout varied industries, from healthcare and finance to leisure and customer support. They’ve even sparked new frontiers in artistic writing and storytelling.
Nonetheless, their huge measurement, resource-intensive coaching processes and potential copyright infringements for generated content material have additionally raised issues about moral utilization, environmental affect, and accessibility. Lastly, whereas more and more enhanced, LLMs could comprise some severe flaws, corresponding to “hallucinating” incorrect info, being biased, gullible, or persuaded into creating poisonous content material.
Is there an Finish?
The evolution of neural networks, from their humble beginnings to the rebellion of huge language fashions, raises a profound philosophical query: Will this journey ever come to an finish?
The trajectory of expertise has all the time been marked by relentless development. Every milestone solely serves as a stepping stone to the subsequent innovation. As we attempt to create machines that may replicate human cognition and understanding, it is tempting to ponder whether or not there’s an final vacation spot, a degree the place we are saying, “That is it; we have reached the head.”
Nonetheless, the essence of human curiosity and the boundless complexities of the pure world recommend in any other case. Simply as our understanding of the universe regularly deepens, the search to develop extra clever, succesful, and moral neural networks could also be an infinite journey.
Anil is a Information Science Evangelist at KNIME.