
Picture by Creator | Canva
DeepChecks is a Python package deal that gives all kinds of built-in checks to check for points with mannequin efficiency, information distribution, information integrity, and extra.
On this tutorial, we are going to find out about DeepChecks and use it to validate the dataset and take a look at the skilled machine studying mannequin to generate a complete report. We may even be taught to check fashions on particular exams as a substitute of producing full experiences.
Why do we want Machine Studying Testing?
Machine studying testing is crucial for making certain the reliability, equity, and safety of AI fashions. It helps confirm mannequin efficiency, detect biases, improve safety in opposition to adversarial assaults particularly in Massive Language Fashions (LLMs), guarantee regulatory compliance, and allow steady enchancment. Instruments like Deepchecks present a complete testing answer that addresses all elements of AI and ML validation from analysis to manufacturing, making them invaluable for creating strong, reliable AI programs.
Getting Began with DeepChecks
On this getting began information, we are going to load the dataset and carry out a knowledge integrity take a look at. This crucial step ensures that our dataset is dependable and correct, paving the way in which for profitable mannequin coaching.
- We are going to begin by putting in the DeepChecks Python package deal utilizing the `pip` command.
!pip set up deepchecks --upgrade
- Import important Python packages.
- Load the dataset utilizing the pandas library, which consists of 569 samples and 30 options. The Most cancers classification dataset is derived from digitized pictures of high-quality needle aspirates (FNAs) of breast plenty, the place every characteristic represents a attribute of the cell nuclei current within the picture. These options allow us to foretell whether or not the most cancers is benign or malignant.
- Break up the dataset into coaching and testing utilizing the goal column ‘benign_0__mal_1’.
import pandas as pd
from sklearn.model_selection import train_test_split
# Load Information
cancer_data = pd.read_csv("/kaggle/enter/cancer-classification/cancer_classification.csv")
label_col = 'benign_0__mal_1'
df_train, df_test = train_test_split(cancer_data, stratify=cancer_data[label_col], random_state=0)
- Create the DeepChecks dataset by offering further metadata. Since our dataset has no categorical options, we depart the argument empty.
from deepchecks.tabular import Dataset
ds_train = Dataset(df_train, label=label_col, cat_features=[])
ds_test = Dataset(df_test, label=label_col, cat_features=[])
- Run the information integrity take a look at on the practice dataset.
from deepchecks.tabular.suites import data_integrity
integ_suite = data_integrity()
integ_suite.run(ds_train)
It can take a couple of second to generate the report.
The information integrity report accommodates take a look at outcomes on:
- Function-Function Correlation
- Function-Label Correlation
- Single Worth in Column
- Particular Characters
- Blended Nulls
- Blended Information Varieties
- String Mismatch
- Information Duplicates
- String Size Out Of Bounds
- Conflicting Labels
- Outlier Pattern Detection
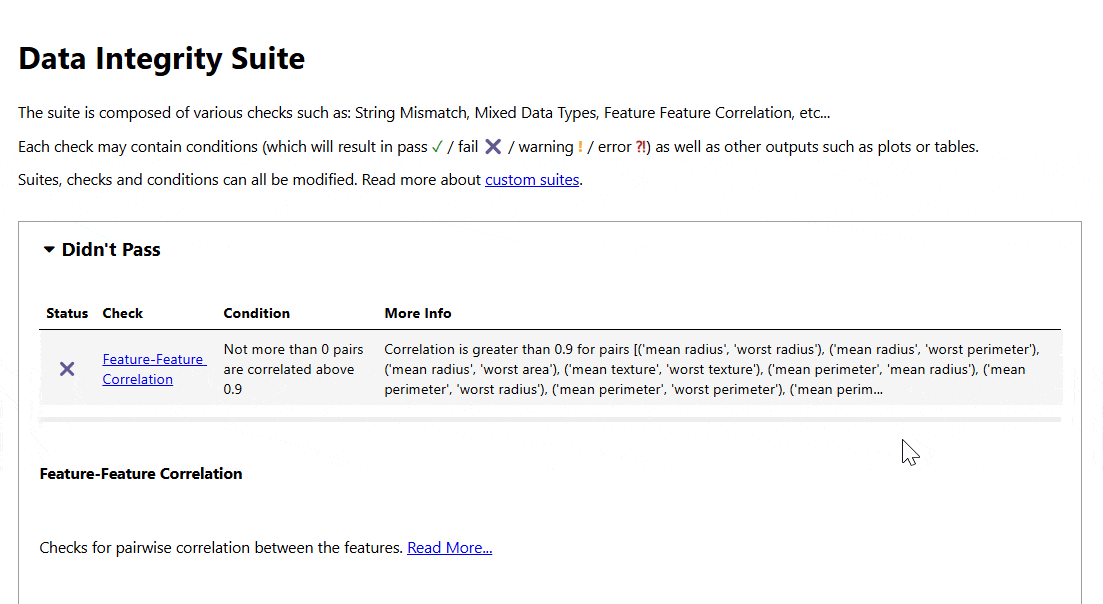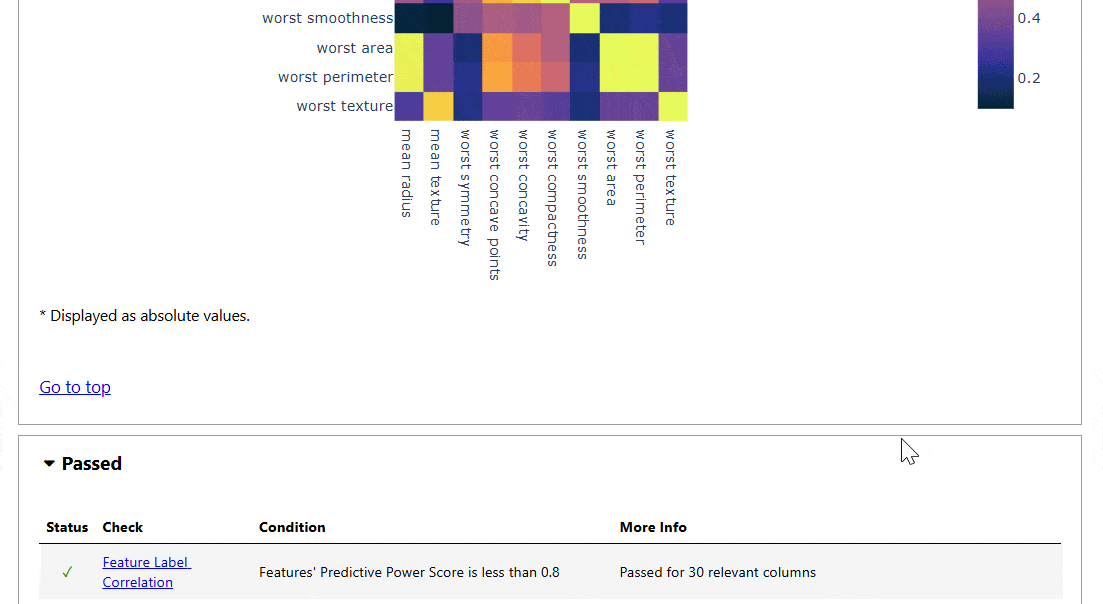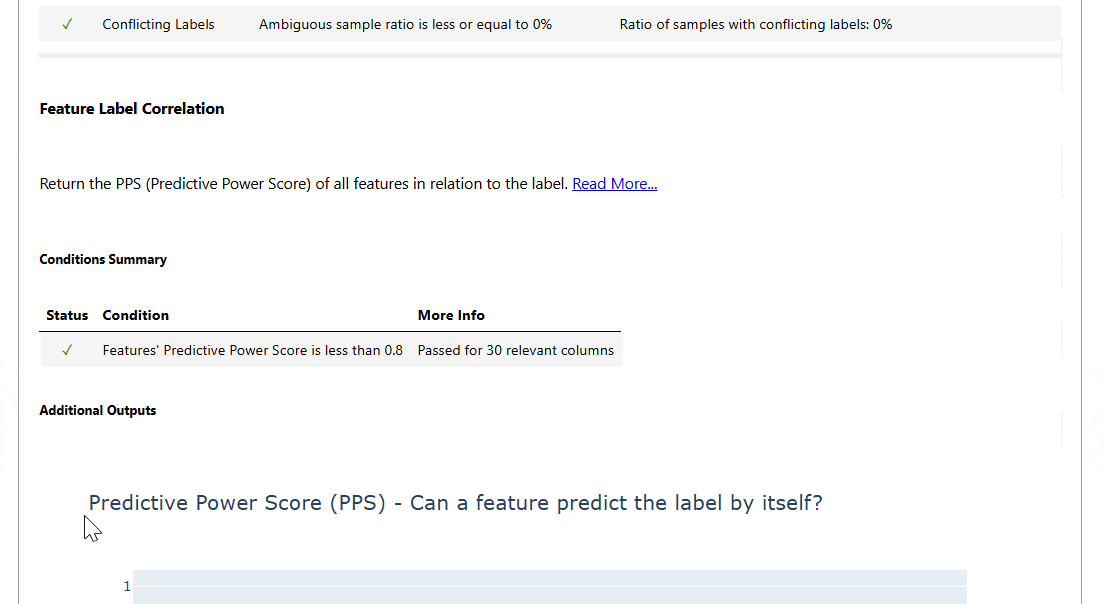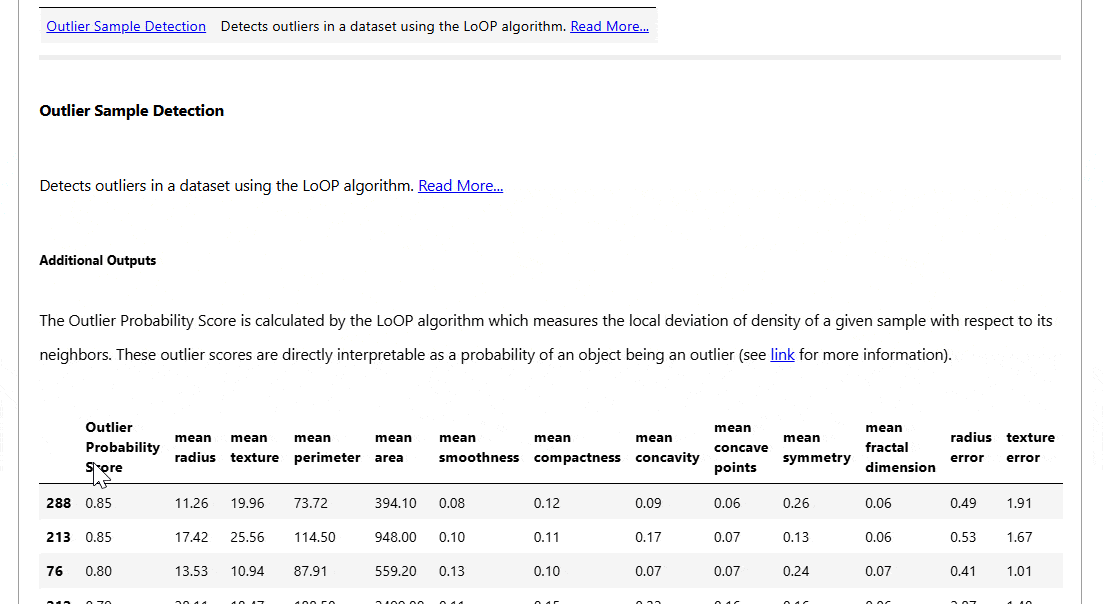
Machine Studying Mannequin Testing
Let’s practice our mannequin after which run a mannequin analysis suite to be taught extra about mannequin efficiency.
- Load the important Python packages.
- Construct three machine studying fashions (Logistic Regression, Random Forest Classifier, and Gaussian NB).
- Ensemble them utilizing the voting classifier.
- Match the ensemble mannequin on the coaching dataset.
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
# Practice Mannequin
clf1 = LogisticRegression(random_state=1,max_iter=10000)
clf2 = RandomForestClassifier(n_estimators=50, random_state=1)
clf3 = GaussianNB()
V_clf = VotingClassifier(
estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)],
voting='onerous')
V_clf.match(df_train.drop(label_col, axis=1), df_train[label_col]);
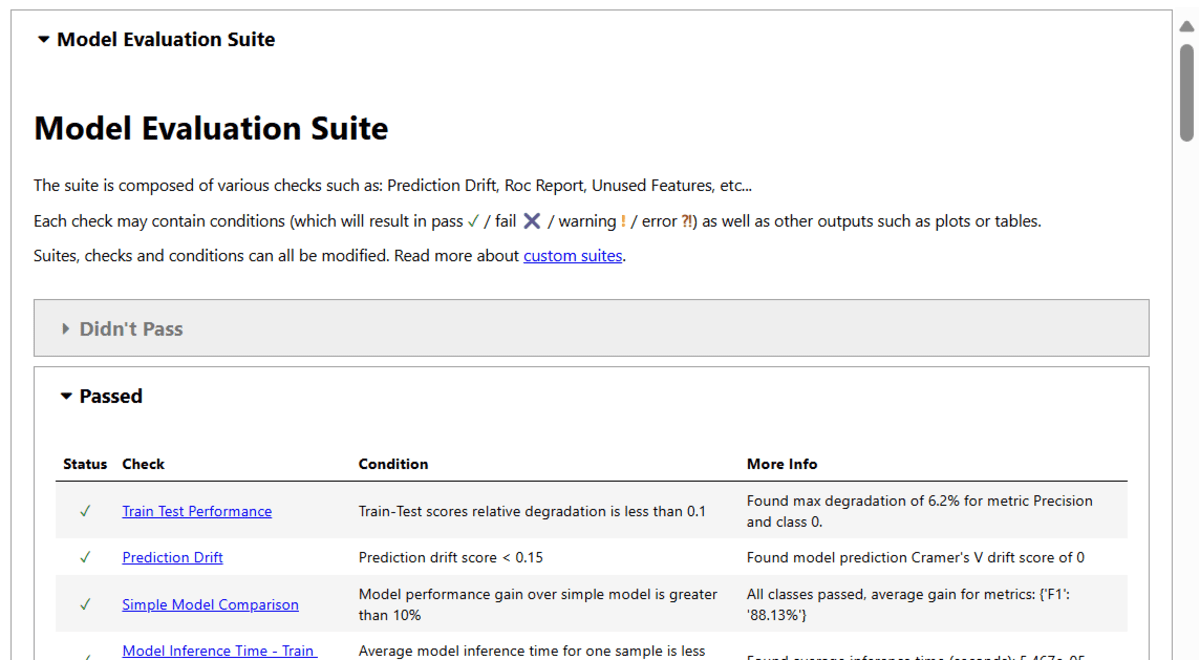
- As soon as the coaching part is accomplished, run the DeepChecks mannequin analysis suite utilizing the coaching and testing datasets and the mannequin.
from deepchecks.tabular.suites import model_evaluation
evaluation_suite = model_evaluation()
suite_result = evaluation_suite.run(ds_train, ds_test, V_clf)
suite_result.present()
The mannequin analysis report accommodates the take a look at outcomes on:
- Unused Options – Practice Dataset
- Unused Options – Check Dataset
- Practice Check Efficiency
- Prediction Drift
- Easy Mannequin Comparability
- Mannequin Inference Time – Practice Dataset
- Mannequin Inference Time – Check Dataset
- Confusion Matrix Report – Practice Dataset
- Confusion Matrix Report – Check Dataset
There are different exams out there within the suite that did not run as a result of ensemble sort of mannequin. If you happen to ran a easy mannequin like logistic regression, you may need gotten a full report.
- If you wish to use a mannequin analysis report in a structured format, you’ll be able to all the time use the `.to_json()` perform to transform your report into the JSON format.
suite_result.to_json()

- Furthermore, it’s also possible to save this interactive report as an internet web page utilizing the
.save_as_html()perform.
Operating the Single Test
If you happen to do not need to run the whole suite of mannequin analysis exams, it’s also possible to take a look at your mannequin on a single verify.
For instance, you’ll be able to verify label drift by offering the coaching and testing dataset.
from deepchecks.tabular.checks import LabelDrift
verify = LabelDrift()
end result = verify.run(ds_train, ds_test)
end result
In consequence, you’re going to get a distribution plot and drift rating.

You possibly can even extract the worth and methodology of the drift rating.
end result.worth
{'Drift rating': 0.0, 'Technique': "Cramer's V"}
Conclusion
The following step in your studying journey is to automate the machine studying testing course of and monitor efficiency. You are able to do that with GitHub Actions by following the Deepchecks In CI/CD information.
On this beginner-friendly, we’ve got discovered to generate information validation and machine studying analysis experiences utilizing DeepChecks. In case you are having bother operating the code, I counsel you take a look on the Machine Studying Testing With DeepChecks Kaggle Pocket book and run it your self.
Abid Ali Awan (@1abidaliawan) is an authorized information scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.